
reference
General process of object detection
Object Detection은 기본적으로 다음과 같은 Stage로 진행된다.
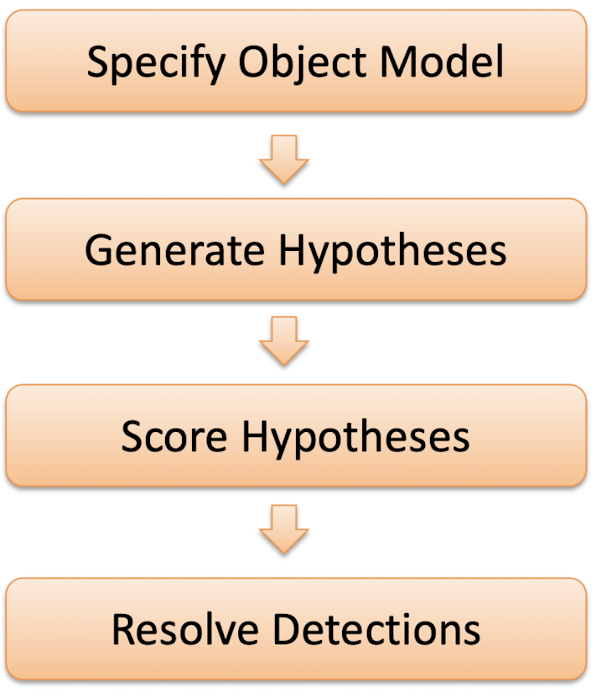
Specify Object Model
Statistical template in bounding box
객체가 이미지 내의 일부 (x,y,w,h)로 정의되며, bounding box 좌표에 대해 정의된 특징을 사용하는 객체 모델링 방법이다.
이 방법은 객체 검색에 초점을 맞추며, 객체와 배경을 빠르게 구별하는 template을 구축한다.
아래 이미지에서 자전거가 있다면 자전거에 대한 template을 만들어 Hog(Histogram of Oriented Gradients)를 진행한 것이 최종 Statistical Template이 된다.

Articulated parts model
객체를 여러 부분의 구성으로 정의한다.
detection 그 자체보다는 pose estimation을 할 때나, graphics 쪽에서 애니메이션을 위해 많이 사용하는 구조이다.

Hybrid template/parts model
template과 parts model의 혼합

3D-ish model
객체는 Affine Transformation 아래에서 3D 평면 패치의 컬렉션으로 정의된다.
3D 객체의 형태와 모양을 보존하면서 2D 이미지로 변환하는 데 사용된다.
Generate Hypothesis
Specify Object Model 단계에서 어떤 Object를 뽑을지를 정했다.
Generate Hypothesis 단계는 Image에서 우리가 찾는 Object일 가능성이 높은 후보들을 결정하는 과정이다.
간략하게 Image에서 객체가 있을 수 있는 영역을 찾는 것이라 할 수 있다.
Sliding Window
슬라이딩 윈도우는 각 scale, location에서 patch만큼 검사하는 방법이다.
결국, sliding window를 진행했다는 것은 image 한 장으로부터 수많은 patch들을 뽑고, 그 patch 각각이 내가 찾는 object가 맞냐 아니냐를 분류하는 것이라 할 수 있다.


Voting from patches/keypoints
image에서 keypoint 또는 patch를 선택하여 투표를 진행하고, 투표 결과를 결합하여 객체를 찾는 방법이다.
Region-based proposal
image에서 객체가 있을 수 있는 영역을 제안하는 방법이다.
최근의 딥러닝과 영역 제안 방법의 발전으로, 컨볼루션 신경망(CNN) 기반의 객체 검출기가 빠르게 발전하고 있다.
(최근 많이 사용하는 방법이다)
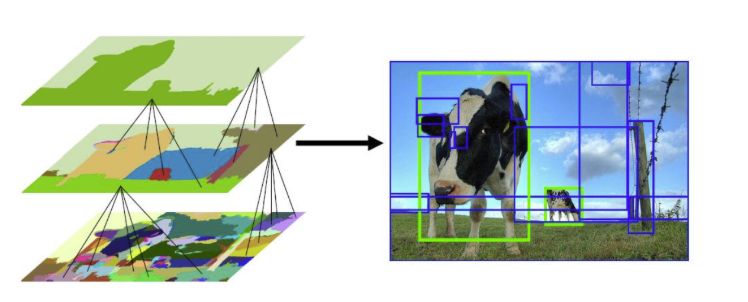
Sliding Window vs Region Proposals
Sliding Window
image에서 고정된 크기의 윈도우를 이동시키면서 객체를 검출하는 방법이다.
이 방법은 위치, 스케일(때로는 종횡비)에 대한 포괄적인 검색을 수행한다.
일반적으로 100K개의 후보가 생성된다.
이 방법은 간단하고, 컨볼루션을 통해 속도 향상이 가능하며, 반복이 가능하다.
하지만, 많은 후보가 있다고 한들 적합한 Object가 아닐 수 있다.
Region Proposals
image에서 객체가 있을 수 있는 영역을 제안하는 방법이다.
이 방법은 이미지의 윤곽선/패턴을 기반으로 다양한 종횡비/크기의 영역을 찾는다.
일반적으로 2-10K개의 후보가 생성된다.
전처리가 필요하며(현재 1-5초), 무작위로 생성되므로 반복이 불가능하다.
하지만, 매우 적합한 Object 후보를 제공할 가능성이 높다.
Score Hypothesis
알려진 Classifier를 이용해 진행한다.
Region classification problem라면, Gradient based 또는 CNN features와 같은 feature 추출 방법이 사용되며, 다양한 classifier가 사용될 수 있다.
Resolve Detections
제안된 Object들을 최종적으로 결정하는 단계이다.
전체 set를 기반으로 제안된 Object들을 Rescore를 하게 되고, 이를 통해 중복 검출이나 잘못된 검출을 제거하게 된다.
Non-max suppression
image 주변에 있는 patch들까지 높은 score를 갖게 되는 문제를 해결 하기 위해, object 주변에 존재하는 bounding box 들 중 제일 좋은거 하나만 남기고 제거하는 방법이다.
가장 좋은 score를 가진 bounding box를 제외한 나머지 bounding box에 대해, 가장 좋은 score를 가진 bounding box와의 IoU(Intersection over Union)을 계산한다.
IoU 값은 두 box 사이의 겹치는 부분을 나타내며, 0~1의 범위를 가지게 된다. (0:겹치는 부분 없음, 1:모두겹침)
IoU 임계값(하이퍼파라미터)을 설정하여, 두 개의 bounding box가 같은 object인지 여부를 결정한다.
만약 IoU 값이 IoU 임계값보다 크게되면, 같은 Object로 간주하고, score가 높은 box만 남기고 나머지 box를 제거한다.
이 단계를 반복하게 되면, 겹치게 되는 모든 (score가 낮은) box를 제거할 수 있게 되며, 최종적으로 가장 높은 score의 box만 남게 된다.


Context/reasoning
image에서 Object가 있을 수 있는 영역을 제안하고, 이러한 영역을 Classifier에 적용하여 Object가 있는지 여부를 결정하는 방법이다.
Statistical Template Approach
Dalal-Triggs Pedestrian Detector
참고 : https://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf
Navneet Dalal, Bill Triggs가 제안한 Histogram of Oriented Gradients (HOG) 알고리즘을 기반으로 하는 보행자 검출 방법이다.
Dalal-Triggs detector 과정

1. 각 위치와 스케일에서 고정된 크기(64x128 pixel)의 window을 추출한다.
2. 각 window 내에서 HOG (Histogram of Oriented Gradients) features을 계산한다.
(* HOG(Histogram of Oriented Gradients) : SIFT (Scale-Invariant Feature Transform; 서로 다른 두 이미지에서 SIFT 특징을 각각 추출한 다음에 서로 가장 비슷한 특징끼리 매칭해주면 두 이미지에서 대응되는 부분을 찾을 수 있다는 것이 기본 원리)와 비슷하다)
3. linear SVM 분류기로 window을 점수화한다.
4. non-maxima suppression을 수행하여 점수가 낮은 겹치는 detection을 제거한다.
R-HOG detector
R-HOG(Rectangular HOG)는 HOG(Histogram of Oriented Gradients)의 한 종류로, image를 직사각형 블록으로 나누고 각 블록 내에서 그라디언트의 방향에 따라 히스토그램을 계산하는 방법이다.
* 해당 detectors는 주로 실루엣 윤곽선(특히 머리, 어깨, 발)에 의존한다.

(a): 학습 예제의 평균 그라디언트 이미지. (이 자체를 feature로 이용한다.)
(b): 각 "pixel"은 pixel 중심의 블록에서 최대 양(positive)의 SVM 가중치를 나타낸다.
(c): (b)와 마찬가지로로 음(negative)의 SVM 가중치를 나타낸다.
(d): 테스트 이미지.
(e): (d)를 통해 계산된 R-HOG descriptor.
(f,g): R-HOG descriptor를 각각 양(positive)의 및 음(negative)의 SVM 가중치로 가중된 결과.
weighted by SVM weights : SVM 분류기의 가중치를 사용하여 HOG 특징을 조정하는 것
statistical template approach의 장점
- 얼굴, 자동차, 서있는 보행자와 같은 변형되지 않은 객체(non-deformable)에 대해 잘 작동함
- 검출 속도 빠름
statistical template approach의 단점
- sliding window는 변형된 객체(deformable objects)에 대해서는 잘 작동하지 않음.
- 가려진 상태에서는 잘 작동하지 않음
- 많은 training data가 필요함
극복하는 방법
1. Feature engineering은 중요하다
2. sliding window는 detect가 가능한 가장 작은 object의 size로 선택한다
3. positive example를 생성하기 위해 rotate, translate, scale, mirror version을 만들어 training data의 양을 늘린다.
4. negative example를 무작위로 sampling하여 detector를 훈련시키고, score가 -1보다 큰 negative sample을 고르면서, high-score를 가진 모든 negative example이 메모리에 저장될 때까지 반복한다. (bootstrapping 방법)
'🤖 ai logbook' 카테고리의 다른 글
| [RL] Q 러닝(Q-learning) (0) | 2023.08.07 |
|---|---|
| [CV] Single-stage Models (YOLO, YOLOv2/YOLO9000) (0) | 2023.07.31 |
| [CV] Two-stage Models (R-CNN, SPPNet, Fast R-CNN, Faster R-CNN) (0) | 2023.07.29 |
| [CV] Parts-based Models & Deformable Part Model (DPM) (0) | 2023.07.29 |
| 베이즈 정리(Bayes’ theorem) & 마르코프 모델(Markov Models) (0) | 2023.07.14 |
| [NLP/자연어처리/Python] koGPT2 ChatBot 실습 (0) | 2023.07.09 |
| [cs231n/Spring 2023] Lecture 5: Image Classification with CNNs (0) | 2023.07.09 |
| [NLP/자연어처리/Python] text generation 실습 (transformer 언어 번역) (0) | 2023.07.09 |