
reference
YOLO web : https://pjreddie.com/darknet/yolo/
YOLO2 youtube : https://www.youtube.com/watch?v=VOC3huqHrss
YOLO3 youtube : https://www.youtube.com/watch?v=MPU2HistivI
YOLO (You Only Look Once)
YOLO 계열은 object detection에서 널리 사용되는 One-Stage Detector의 대표 모델이다.
YOLO는 단일 Convolutional Neural Network(CNN)을 사용해 이미지 내의 여러 개의 bounding box와 각 box의 클래스 확률을 동시에 예측할 수 있다.
전체 image를 한 번에 처리하는 end-to-end 방식 (one evaluation에서 처리된다)으로, 이는 image pixel에서 bounding box 좌표 및 class 확률을 동시에 예측하는 회귀 문제로 프레임화 된다.
일반적으로 non-maximum suppression와 같은 후처리 단계는 필요하지 않다.
Titan X GPU에서 45fps의 매우 빠른 속도를 자랑하며, faster version에서는 155fps의 속도이다.
(최첨단 검출기(state-of-the-art detector) 보다는 성능이 좋은 것은 아니다.)
Network Design

GoogLeNet model을 base로 하며, 24개의 convolutional layers과 2개의 fully connected layers으로 구성되어 있다.
(faster version의 경우 9개의 convolutional layers만 사용한다)
여기서, YOLO의 핵심 아이디어 중 하나는 전체 이미지를 SxS 그리드로 나누는 것이다. (논문에서는. S=7).

이렇게 나누어진 각 그리드 셀은 셀 중심에 떨어지는 object를 감지하는 책임이 생긴다.
각 그리드 셀은 두 가지 종류의 예측을 하게 된다.
첫번째로 B개의 Bounding box를 예측한다. ([x,y,w,h,confidence], confidence : object를 포함하고 있는 확률)
두 번째로 각 셀은 C개의 조건부 class 확률을 예측한다.
이 모든 예측은 하나의 tensor로 인코딩 되며, 이 tensor의 차원은 SxSx(Bx5+C)가 된다.
예를 들어, PASCAL VOC 데이터셋에서는 B가 2(각 셀이 두 개의 bounding box를 예측)이고 C가 20(객체 클래스가 20개)이므로, 최종적인 출력 텐서의 차원은 7x7x30가 된다.
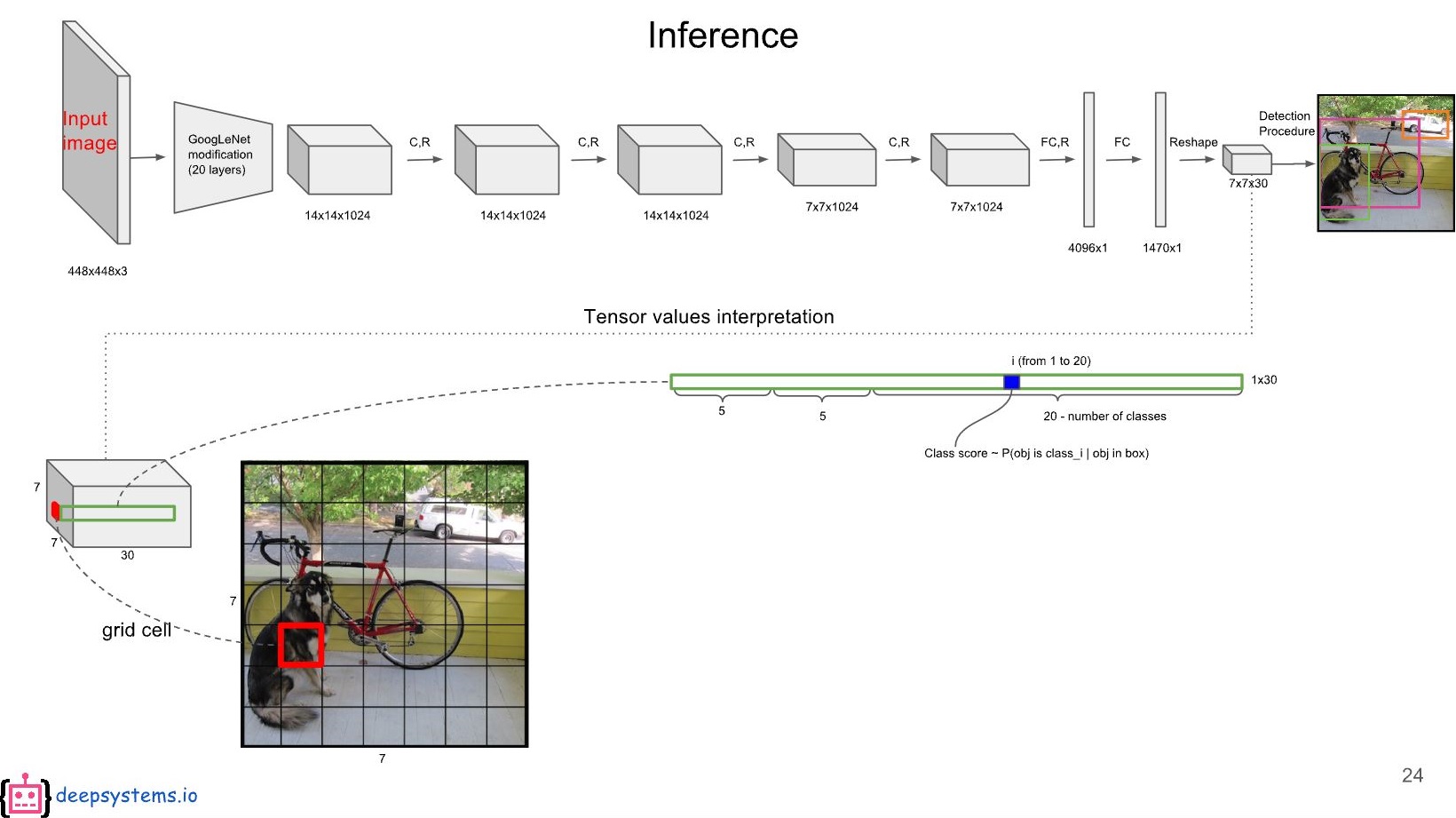
더 자세하게 설명하면, 해당 예시에서 첫 번째 5에는 첫 번째 Bounding box의 x, y, w, h, confidence가 들어가게 되고, 두 번째 5에는 두 번째 Bounding box의 x, y, w, h, confidence가 들어가게 된다.
그리고 그 이후에는 20개의 객체 클래스에 대한 조건부 확률값 $P(Class_{i}|Object)$ 이 채워지게 된다.

Loss Function
YOLO의 Loss Function은 여러 부분(Bounding box Coordinate Loss, Object confidence Loss, Class probability Loss)으로 이루어져 있으며, 이를 통해 다양한 종류의 prediction error를 다룰 수 있다.
YOLO의 Loss function을 살펴보면 다음과 같다.
$$\begin{align}
\ & \lambda_{coord} \sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbb{1}_{ij}^{obj} \Big[ (x_i - \hat{x}_i )^2 + (y_i - \hat{y}_i )^2 \Big] \\\
\ & \qquad + \lambda_{coord} \sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbb{1}_{ij}^{obj} \Bigg[ \Big( \sqrt{w_i} - \sqrt{\hat{w}_i} \Big)^2 + \Big( \sqrt{h_i} - \sqrt{\hat{h}_i} \Big)^2 \Bigg] \\
\ & \qquad \qquad + \sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbb{1}_{ij}^{obj} \Big( C_i - \hat{C}_i \Big)^2 \\
\ & \qquad \qquad + \lambda_{noobj} \sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbb{1}_{ij}^{noobj} \Big( C_i - \hat{C}_i \Big)^2 \\
\ & \qquad \qquad + \sum_{i=0}^{S^2}\mathbb{1}_{i}^{obj} \sum_{c \ \in \ \text{classes}}\Big( p_i(c) - \hat{p}_i (c) \Big)^2 \\
\end{align}$$
가장 중요한 것은 셀 i의 j번째 bbox predictor가 해당 예측에 책임을 가지고 있다는 것이다.
$λ_{coord}$ : bounding box의 정확도를 더 강조하기 위해 곱하는 상수 (기본값: 5)
1. Bounding box Coordinate Loss
ground truth 값과 얼마나 차이 나는지(true positive에 대한 예측이 잘못된 경우의 Coordinate penalty)를 측정하는 Loss function 부분이다.
mean squared error를 사용한다.
$\begin{align}
\ & \lambda_{coord} \sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbb{1}_{ij}^{obj} \Big[ (x_i - \hat{x}_i )^2 + (y_i - \hat{y}_i )^2 \Big] \\\
\ & \qquad + \lambda_{coord} \sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbb{1}_{ij}^{obj} \Bigg[ \Big( \sqrt{w_i} - \sqrt{\hat{w}_i} \Big)^2 + \Big( \sqrt{h_i} - \sqrt{\hat{h}_i} \Big)^2 \Bigg] \\
\end{align}$
2. Object confidence Loss
각 bounding box에 대해 그 안에 object가 있을 확률을 나타내는 confidence score를 예측하는 Loss function 부분이다.
만약 bounding box가 object를 포함하고 있다면, 이 예측된 confidence score가 1에 가까워야 한다. 만약 그렇지 않다면, 이 score는 0에 가까워야 한다.
Bounding box에서 object가 감지되는 경우의 confidence penalty
$\sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbb{1}_{ij}^{obj} \Big( C_i - \hat{C}_i \Big)^2$
Bounding box에서 object가 감지되지 않는 경우의 confidence penalty
$\lambda_{noobj} \sum_{i=0}^{S^2}\sum_{j=0}^{B} \mathbb{1}_{ij}^{noobj} \Big( C_i - \hat{C}_i \Big)^2$
이때, object가 감지되지 않은 경우에 가중치를 곱해주는 이유는 일반적으로 object가 없는 그리드 셀이 훨씬 많기 때문에 불균형 문제를 완화하기 위해서이다.
3. Class probability Loss
각 그리드 셀이 어떤 class의 object를 포함하고 있는지를 예측하는 Loss function 부분이다.
object가 감지되는 경우에 Class prediction penalty를 예측한다.
$\sum_{i=0}^{S^2} \mathbb{1}_{i}^{obj} \sum_{c \ \in \ \text{classes}}\Big( p_i(c) - \hat{p}_i (c) \Big)^2$
단점
object의 위치를 정확하게 예측하는데 어려움이 있다.
가까운 object 및 작은 object의 detection에 어려움이 있다.
YOLOv2/YOLO9000

YOLOv2는 YOLO의 두 번째 버전으로, 정확도를 크게 향상하면서도 더 빠르게 만드는 것이 목표였다.
Backbone의 경우, YOLO에서 GoogLeNet 사용한 것과 달리 YOLOv2는 DarkNet-19를 사용한다. (VGG-19와 유사하다)
YOLO와 비교하여 YOLOv2의 차이점은 다음과 같다.
Batch normalization
모든 Conv Layer에 배치 정규화를 추가하면서, dropout의 필요성을 제거하고 mAP를 2% 증가시켰다. (과적합 방지)
High-resolution classifier
YOLO는 pre-training에 224x224, fine-tuning에 448x448 이미지를 사용했다. YOLOv2에서는 처음부터 448x448 이미지를 사용한다.
Convolutional with Anchor Boxes
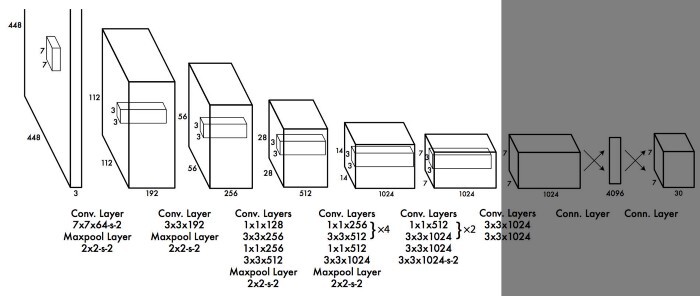
YOLO에서 bounding box 예측을 담당했던 FC layers를 제거하고 Anchor Boxes를 사용해 bounding box를 예측했다.
이는 Faster R-CNN과 유사한 방식으로, object의 정확한 위치를 예측하는 대신 각 anchor box와 object와의 차이값(offsets)을 예측하게 된다.
Dimension Clusters
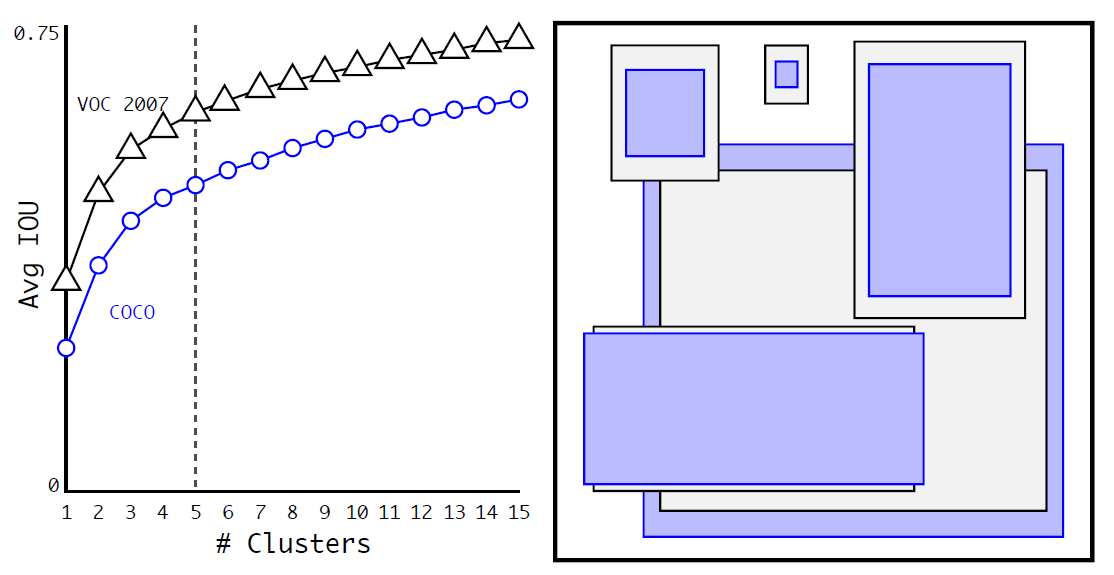
k-means 알고리즘을 사용하여 anchor box의 크기와 비율을 결정하는 방법이다.
YOLOv2에서는 train sets 내의 모든 bounding box에 대해 k-means 클러스터링을 실행하고, 각 그리드 셀에 대해 상위 K 클러스터의 중심을 찾아 k개의 anchor를 찾아낸다.
Direct location prediction

위치 예측에 대한 제약이 없어, 초기 반복에서 불안정한 문제를 해결하기 위해 도입되었다.
각 bounding box에 대해 5개의 좌표($t_x$, $t_y$, $t_w$, $t_h$, $t_o$)를 예측하고, 시그마 함수를 적용하여 가능한 offset 범위를 0과 1 사이로 제한한다.
k-means를 통해 얻은 bounding box prior는 $p_w$, $p_h$일 때, 시각화를 한 그림은 다음과 같다.

$$\begin{align}
b_x & = \sigma(t_x) + c_x \\
b_y & = \sigma(t_y) + c_y \\
b_w & = p_w \ e^{t_w} \\
b_h & = p_h \ e^{t_h} \\
\Pr(\text{object}) \star IOU(b, \text{object}) & = \sigma(t_o) \\
\end{align}$$
이를 통해 mAP를 5% 증가시킬 수 있었다.
Fine-grained features
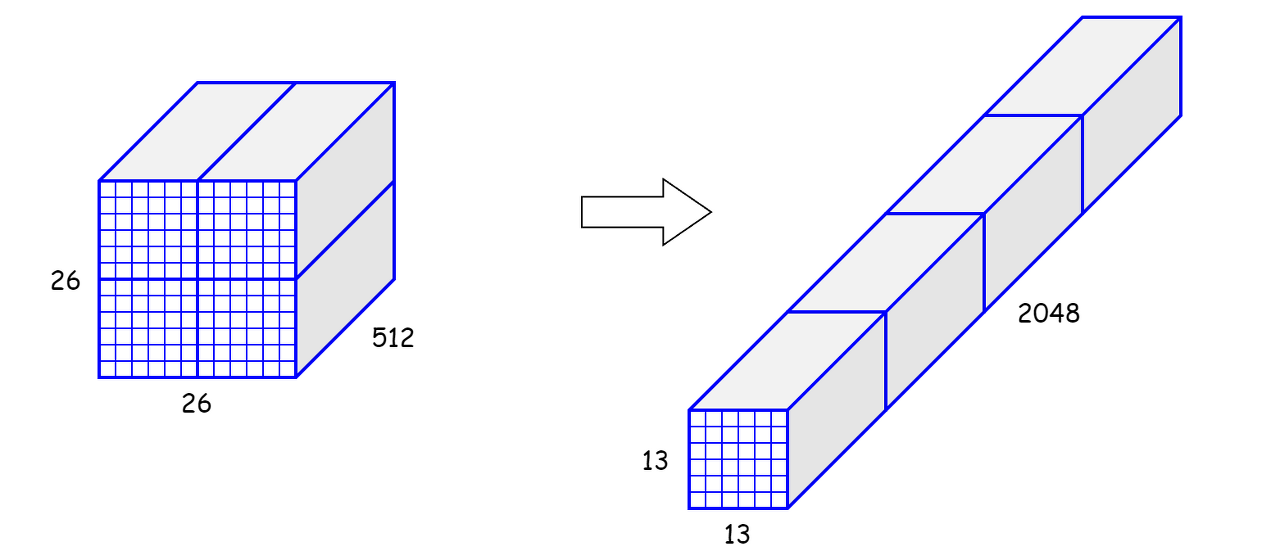
YOLO v2는 최종적으로 13x13 크기의 feature map을 출력한다.
원래 YOLO에서는 마지막 layer의 feature map만 사용해 작은 object에 대한 정보가 사라졌으나,
YOLO v2에서는 conv16 (26x26x512)과 conv24 (13x13x1024) 두 개를 사용하여 object 검출 성능을 향상했다.
Multi-scale training
다양한 input size에서 예측할 수 있도록 훈련하는 방법에 대해 설명한다.
원래 YOLO에서는 448x448의 input image를 사용했다.
반면에, YOLOv2 모델은 오직 Conv Layer와 Pooling Layer만 사용하기 때문에 입력 크기에 제한이 없다.
이를 이용하여, YOLO v2에서는 input image 크기를 고정하는 대신, 10개의 배치마다 YOLOv2는 모델을 훈련할 다른 image 크기를 무작위로 선택한다.
(YOLO 모델은 32의 배수로 다운샘플링하기 때문에, {320, 352, ..., 608} 크기의 image를 가져오게 된다.)
'🤖 ai logbook' 카테고리의 다른 글
| [paper] ChatDev - 소프트웨어 개발을 위한 통신 에이전트(Communicative Agents for Software Development) (0) | 2023.08.16 |
|---|---|
| [RL] Actor-Critic (0) | 2023.08.10 |
| [RL] DQN(Deep Q-Network) - 작성중 (0) | 2023.08.08 |
| [RL] Q 러닝(Q-learning) (0) | 2023.08.07 |
| [CV] Two-stage Models (R-CNN, SPPNet, Fast R-CNN, Faster R-CNN) (0) | 2023.07.29 |
| [CV] Parts-based Models & Deformable Part Model (DPM) (0) | 2023.07.29 |
| [CV] Object Detection & Statistical Template Approach(Dalal-Triggs Pedestrian Detector) (0) | 2023.07.19 |
| 베이즈 정리(Bayes’ theorem) & 마르코프 모델(Markov Models) (0) | 2023.07.14 |