
reference : https://wikidocs.net/book/6038
공부하다 보면 계속 등장하는데 계속 까먹어서; 정리
Bayes’ theorem
Bayes’ theorem은 두 확률 변수의 사전 확률과 사후 확률 사이의 관계를 나타내며,
불확실성 하에서 의사 결정문제를 수학적으로 다룰 때 중요하게 이용된다.
$a$ 일 때 $b$ 일 확률은 $b$ 일 때 $a$ 일 확률에 $b$ 의 확률을 곱한 것을 $a$의 확률로 나눈 것과 같다.
$$P(b|a) = \frac{P(a|b)P(b)}{P(a)}$$
예를 들어, 오전에 흐리면 오후에 비가 오는 확률인 $P(비∣흐림)$을 계산하고 싶다고 하자. 다음 정보에서 시작한다.

- 오후에 비가 온 날 중 80%는 오전부터 흐렸다. $P(흐림∣비)$
- 오전에 흐린 날이 40%다. $P(흐림)$
- 오후에 비가 온 날이 10%다. $P(비)$
베이즈 규칙을 적용해 계산하면 (0.1)(0.8)/(0.4)=0.2를 얻는다.
오전에 흐리면 오후에 비가 올 확률이 20%라는 뜻이다
.
Markov Models
Markov assumption이란 현재 상태가 이전의 유한한 고정된 상태의 수에만 의존한다는 가정이다.
(모델링이나 분석을 단순화하기 위해 시스템이나 확률 과정이 Markov property를 따른다고 가정하는 것을 의미.
여기서, Markov property (마르코프 특성)이란, 미래 상태가 현재 상태에만 의존하고 과거 상태에는 영향을 받지 않는 특성을 말한다.)
시간이 지남에 따라 변수의 값이 어떻게 변화하는지를 고려하고 싶을 때,
일정 기간 동안의 불확실성을 다룰 때 사용한다.
가장 간단한 Markov Model인 Markov chain (또는 Markov Process) 를 "날씨 예측"을 예시로 이해해보자.
예를 들어 맑은 날과, 비 오는 날이 존재한다면
$X_t$ : Weather at time $t$ 와 같이 정의할 수 있을 것이다. ($X_0$ : 0일의 날씨)
만약 이 작업을 오랜 기간 동안 진행한다면, 당연히 엄청난 양의 데이터가 생길 것이고,
1년 동안 날씨에 대한 데이터를 추적한다면 이전 365일을 기준으로 내일 날씨를 예측할 수 있게 되지만,
처리하기 위한 계산량이 많을 것이다.
이를 도와주기 위해 ( 모델을 단순화하고 계산을 쉽게 하기 위해) Markov 가정을 사용한다.
오늘의 날씨를 예측하기 위해 이전의 모든 날씨를 의존하는 것이 아닌,
현재 상태를 예측하는데 도움이 되는 이전 상태 (어제의 날씨, 또는 2일 전의 날씨) 하나만을 다룰 것이다.
그리고 여기(Markov assumption)에 무작위 변수 전체를 함께 배치시키면서
결과적으로 Markov assumption을 따르는
임의 변수의 Sequence를 생성하게 될 때 이를 Markov chain이라 한다.
다음과 같은 Transition Model이 존재한다.
(한 상태에서 다음 상태로 어떻게 전환(transition)하는지에 대한 설명이 작성된 것)
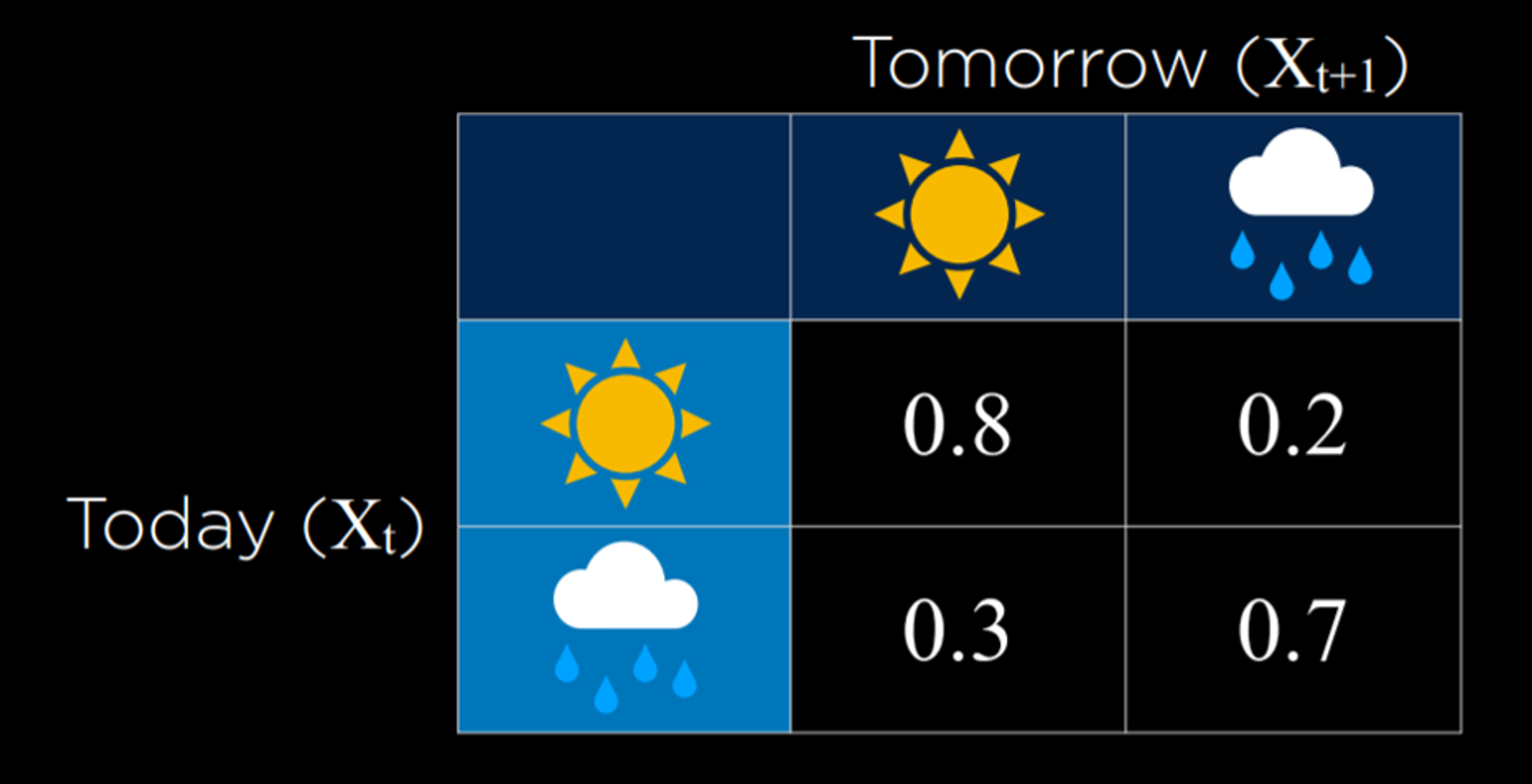
Transition Mode을 사용하면 Markov chain을 샘플링할 수 있다.
비오는 날이나 맑은 날로 시작하여,
오늘의 날씨에 따라 내일의 날씨가 맑을지 비 올지의 확률을 기반으로 다음 날을 샘플링한다.
그런 다음, 내일의 확률을 기반으로 모레의 확률을 조건부로 설정하고,
이를 계속 반복하여 Markov chain를 생성한다.
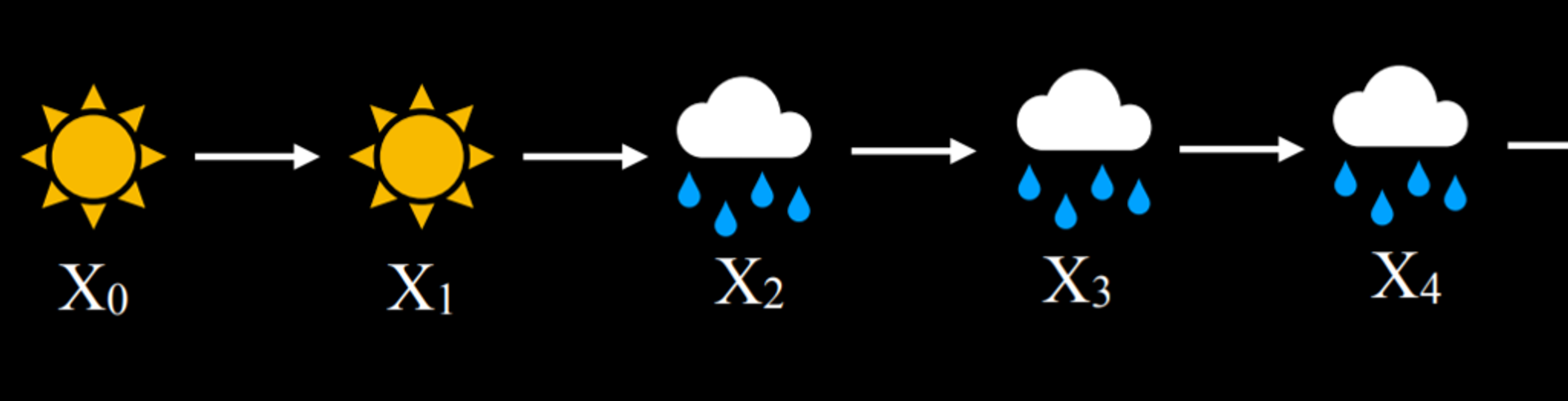
참고 : http://firsttimeprogrammer.blogspot.com/2014/08/weather-forecast-through-markov-chains.html
import numpy as np
import random as rm
import time
states = ["sun","rain"]
transitionName = [["ss","sr"],["rs","rr"]]
transitionMatrix = [[0.8,0.2],[0.3,0.7]]
def weatherForecast(days):
weatherToday = "sun"
i = 0
print(f"X_0 : {weatherToday}")
while i < days:
if weatherToday == "sun":
change = np.random.choice(transitionName[0],replace=True,p=transitionMatrix[0])
if change == "ss":
pass
else:
weatherToday = "rain"
elif weatherToday == "rain":
change = np.random.choice(transitionName[1],replace=True,p=transitionMatrix[1])
if change == "rr":
pass
else:
weatherToday = "sun"
print(f'X_{i+1} : {weatherToday}')
i += 1
predic_size = 20
weatherForecast(predic_size)X_0 : sun
X_1 : rain
X_2 : rain
X_3 : rain
X_4 : rain
X_5 : rain
X_6 : sun
X_7 : sun
X_8 : rain
X_9 : rain
X_10 : sun
X_11 : sun
X_12 : rain
X_13 : sun
X_14 : sun
X_15 : rain
X_16 : rain
X_17 : rain
X_18 : rain
X_19 : sun
X_20 : sun
Hidden Markov Model
HMM(Hidden Markov Model)은 시스템이 은닉된 상태와 관찰가능한 결과의 두 가지 요소로 이루어졌다고 보는 Markov 모델이다.
로봇이 미지의 영역을 탐색하는 경우, 로봇의 위치(Hidden State)가 어떤지 확인할 수 없지만,
주변에 장애물이 얼마나 멀리 있는지 감지하는 로봇 센서 데이터(Observation)를 이용해 무언가를 추론할 수 있다.
또 다른 예로, 음성 인식 시스템이 존재할 때, 실제로 말하는 단어(Hidden State)는 AI는 알 수 없다.
그저 일부 오디오 파형(Observation)을 가지고 말한 단어가 무엇인지 추론할 수 있을 뿐이다.
Markov chain에서 다뤘던 날씨로 다시 돌아가서,
날씨가 맑은지 비가 오는지 모를 때(Hidden State),
우리는 건물 안에서 건물 카메라를 이용해 직원이 건물 안으로 우산(Observation)을 들고 오는지 여부만 확인할 수 있을 때
그 정보를 사용하여 날씨를 모르는 상태에서 날씨를 예측할 수 있다.
다음과 같은 Sensor Model이 존재한다.

이 Sensor Model을 통해 사람들이 우산을 가져왔는지 여부를 관찰함으로써
외부 날씨가 어떨지 합리적으로 예측할 수 있다.
여기서 Sensor Markov Assumption를 진행할 수 있는데,
이는 Observation($E_t$) 해당 State($X_t$)에만 의존한다는 가정이다.
(실제 상황에서는 다른 요인들도 증거 변수에 영향을 미칠 수 있지만
그러한 정보들은 제외하고, 숨겨진 상태만이 관찰에 영향을 미친다고 가정)

Hidden Markov Model는 결국 두 개의 Layer가 있는 Markov chain으로 나타낼 수 있으며,
X는 숨겨진 상태를, E는 증거. 즉, 가지고 있는 관찰값을 의미한다.
Hidden Markov Model로 다음과 같은 작업을 수행할 수 있다.
- Filtering : 지금까지 주어진 관측치를 통해 현태 상태에 대한 확률 분포를 계산할 수 있다.
- Prediction : 지금까지 주어진 관측값으로 미래 상태에 대한 확률 분포를 계산할 수 있다.
- Smoothing : 지금까지 주어진 관측값으로 과거 상태에 대한 확률 분포를 계산할 수 있다.
- Most likely explanation : 지금까지 관찰한 내용을 바탕으로 가장 가능성이 높은 사건을 계산할 수 있다.
chat gpt 참고
import numpy as np
class HMM:
def __init__(self):
# Transition matrix
self.transition_matrix = np.array([[0.8,0.2],[0.3,0.7]])
# Sensor model
self.sensor_model = np.array([[0.2, 0.8],
[0.9, 0.1]])
# Initial state probabilities
self.initial_probabilities = np.array([0.5, 0.5])
def predict_weather(self, observations):
num_states = self.transition_matrix.shape[0]
num_observations = len(observations)
predicted_states = np.zeros(num_observations)
# Forward algorithm
forward = np.zeros((num_observations, num_states))
forward[0] = self.initial_probabilities * self.sensor_model[:, observations[0]]
for t in range(1, num_observations):
forward[t] = np.dot(forward[t-1], self.transition_matrix) * self.sensor_model[:, observations[t]]
# Backward algorithm
backward = np.zeros((num_observations, num_states))
backward[-1] = 1
for t in range(num_observations-2, -1, -1):
backward[t] = np.dot(self.transition_matrix, (self.sensor_model[:, observations[t+1]] * backward[t+1]))
# Calculate smoothed probabilities
smoothed = forward * backward / np.sum(forward * backward, axis=1, keepdims=True)
# Make predictions based on the most probable state
predicted_states = np.argmax(smoothed, axis=1)
return predicted_states
# Usage example
hmm = HMM()
predic_size = 20
umbrella_observations = np.random.choice([0, 1], size=predic_size)
predicted_states = hmm.predict_weather(umbrella_observations)
observation_strings = ['no' if obs == 0 else 'yes' for obs in umbrella_observations]
for observation, state in zip(observation_strings, hmm.predict_weather(umbrella_observations)):
state_string = 'rain' if state == 1 else 'sun'
print(f"Umbrella: {observation} -> States: {state_string}")Observations (Umbrella) -> States:
Umbrella: Yes -> States: sun
Umbrella: Yes -> States: sun
Umbrella: Yes -> States: sun
Umbrella: Yes -> States: sun
Umbrella: No -> States: sun
Umbrella: Yes -> States: sun
Umbrella: No -> States: sun
Umbrella: Yes -> States: sun
Umbrella: Yes -> States: sun
Umbrella: Yes -> States: sun
Umbrella: No -> States: rain
Umbrella: No -> States: rain
Umbrella: Yes -> States: sun
Umbrella: Yes -> States: sun
Umbrella: No -> States: rain
Umbrella: No -> States: rain
Umbrella: Yes -> States: sun
Umbrella: Yes -> States: sun
Umbrella: No -> States: rain
Umbrella: No -> States: rain'🤖 ai logbook' 카테고리의 다른 글
| [CV] Single-stage Models (YOLO, YOLOv2/YOLO9000) (0) | 2023.07.31 |
|---|---|
| [CV] Two-stage Models (R-CNN, SPPNet, Fast R-CNN, Faster R-CNN) (0) | 2023.07.29 |
| [CV] Parts-based Models & Deformable Part Model (DPM) (0) | 2023.07.29 |
| [CV] Object Detection & Statistical Template Approach(Dalal-Triggs Pedestrian Detector) (0) | 2023.07.19 |
| [NLP/자연어처리/Python] koGPT2 ChatBot 실습 (0) | 2023.07.09 |
| [cs231n/Spring 2023] Lecture 5: Image Classification with CNNs (0) | 2023.07.09 |
| [NLP/자연어처리/Python] text generation 실습 (transformer 언어 번역) (0) | 2023.07.09 |
| [NLP/자연어처리/Python] text classification 실습 (0) | 2023.07.08 |