
Standford University - CS231n(Convolutional Neural Networks for Visual Recognition)
Stanford University CS231n: Deep Learning for Computer Vision
✔ reference
YouTube
cs231n 2강 Image classification pipeline - YouTube
Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition - YouTube
Doc
https://yganalyst.github.io/dl/cs231n_1
https://yerimoh.github.io/DL206/
https://biology-statistics-programming.tistory.com/53
https://velog.io/@cha-suyeon/CS231n-Lecture-9-%EA%B0%95%EC%9D%98-%EC%9A%94%EC%95%BD
https://velog.io/@fbdp1202/CS231n-%EC%A0%95%EB%A6%AC-9.-CNN-Architectures-rp6rx3zy
https://yerimoh.github.io/DL206/
https://velog.io/@cha-suyeon/CS231n-4%EA%B0%95-%EC%A0%95%EB%A6%AC-Introduction-to-Neural-Networks
Higher-level representations, image features
선형분류는 간단하고 이해가 쉬우나, geometric viewpoint, visual viewpoint에서의 한계가 있음.
뉴럴 네트워크의 핵심은 이런 선형구조에+ 비선형 구조를 더해두는 방식
CNN 등장 전에 image에서 feature를 뽑아내는 방법은 다음과 같음
→ 인위적으로 feature 추출하는 전통적인 방식으로 image 분류함
→ 허나 deep learning에서는 feature를 추출하는게 아닌, 이미지 그대로 function에 넣어서 동작
Linear Classification에서 사용하는 특징 추출
Color histogram
이미지의 color distribution 을 사용하여 해당 이미지의 feature 로 사용
histogram of oriented gradients (HoG)
8 x 8 patch 를 만들어, 각 patch 마다 9 directional oriented gradients 를 계산하여, 이를 feature 로 사용하는 방법
bag of wards
일정 크기의 랜덤 patch 를 모아 clustering 을 통해 visual words (codebook) 을 만들고,
feature 뽑아내고 싶은 image 를 patch 형태로 바꾸고, codebook 에서 찾아 histogram 을 만들어 이를 feature 로 사용(k-means 방식 사용)
Convolution and pooling
Fully Connected Layer
vector를 길게 펴는 역할을 함

1 number : W 개의 row와 input 사이에 dot product을 취한 결과.
Convolution Layer
여기서 filter는 가중치 vector의 역할을 하게 됨
여기서 depth(3)은 input volume의 full depth(3)에 대해 내적을 함
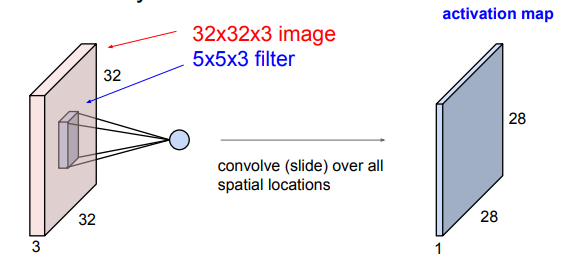
one filter - one activation map
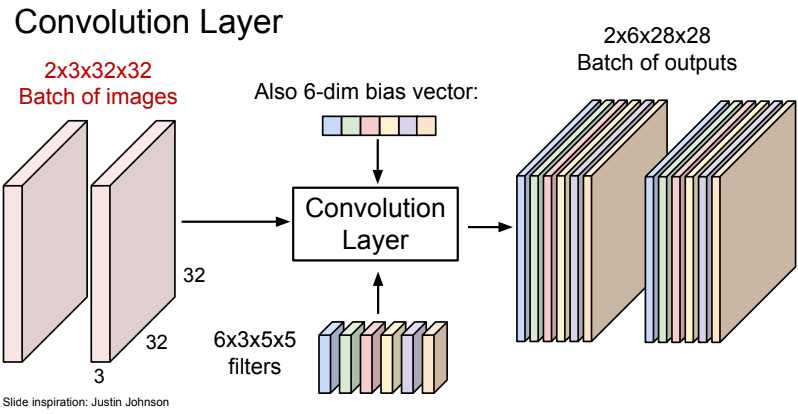
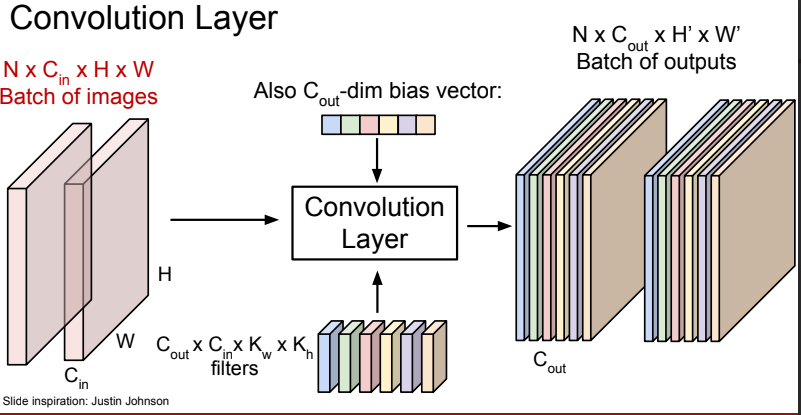
N x C(in) x H x W ⇒ C(out) x C(in) x K(w) x K(h) ⇒ N x C(out) x H’ x W’
- batch dimension : N
- channel dimension : C(in)
- spatial dimension : H, W
- filter 개수 : C(out)
Filter + Stride
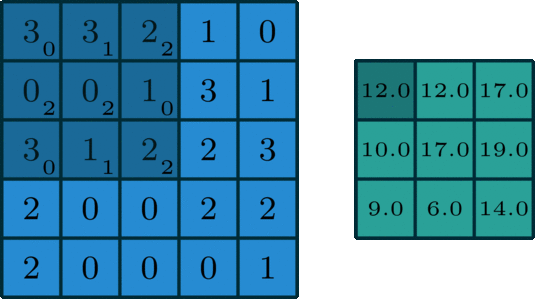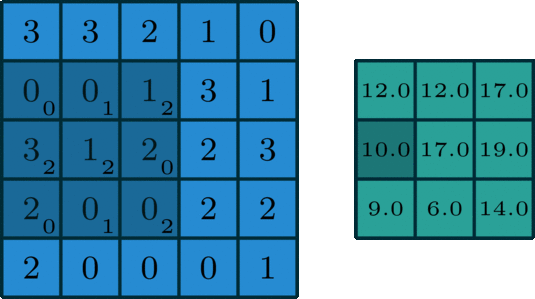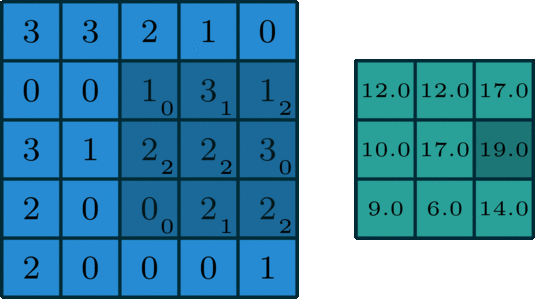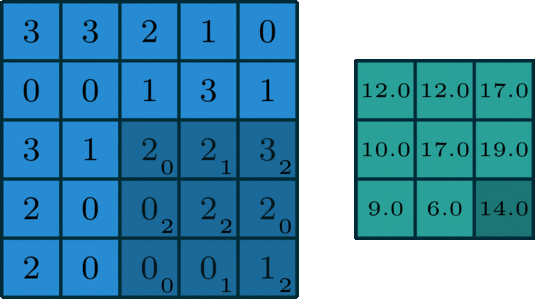

stride 3에서는 output이 생성되지 않는다.
물론 실제 code상에서 예외처리 등을 진행할 수 있지만, stide는 output이 정수가 되도록 해야한다고 기억하자
Padding
Padding을 해주는 이유 : Padding을 하지 않으면, 계속 size가 줄어들게 되어 결국 shrinking되어버린다. Shrinking too fast is not good, doesn’t work well.
padding을 통해 사이즈를 유지하면서 filter의 중앙이 닿지 않는 곳에도 연산을 할 수 있다

For convolution with kernel size K, each element in the output depends on a K x K receptive field in the input Each successive convolution adds K – 1 to the receptive field size With L layers the receptive field size is 1 + L * (K – 1)
Problem: For large images we need many layers for each output to “see” the whole image image → Solution: Downsample inside the network (Strided 사용, Pooling layer 사용)
Convolution layer: summary
Let’s assume input is W1 x H1 x C
Conv layer needs 4 hyperparameters:
- Number of filters K
- The filter size F
- The stride S
- The zero padding P
This will produce an output of W2 x H2 x K
where:
- W2 = (W1 - F + 2P)/S + 1
- H2 = (H1 - F + 2P)/S + 1
Number of parameters: (F*F)*C*K and K biases
→ if +1 for bias, ((F*F)*C +1)*K
1x1 convolution lyaer → perfect sense

brain/neuron view of CONV Layer

- 각각의 뉴런의 입력값이 같은 지역에 연결되어 있다 → local connectivity
- 각각의 뉴런이 동일한 파라미터를 공유한다 → parameter sharing
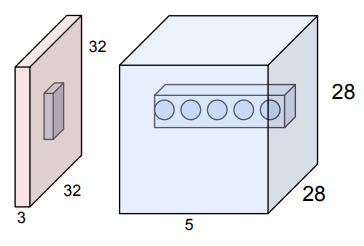
- 각각의 뉴런(dot)이 같은 이미지를 바라본다 (local activity)
- 하지만, 각각의 뉴런(dot)은 서로 다른 weight를 가진다.
Pooling Layer
이미지를 downsample하는 것
- makes the representations smaller and more manageable
- operates over each activation map independently
→ Weight 없고, Padding 도 없다

- No learnable parameters
- Introduces spatial invariance
Let’s assume input is W1 x H1 x C
Conv layer needs 2 hyperparameters: (K, P는 필요하지 않음)
- The spatial extent F
- The stride S
This will produce an output of W2 x H2 x C
where:
- W2 = (W1 - F )/S + 1
- H2 = (H1 - F)/S + 1
Number of parameters: 0
Summary
- ConvNets stack CONV,POOL,FC layers
- Trend towards smaller filters and deeper architectures
- Trend towards getting rid of POOL/FC layers (just CONV)
- Historically architectures looked like [(CONV→RELU)*N→POOL?]*M→(FC→RELU)*K,SOFTMAX where N is usually up to ~5, M is large, 0 <= K <= 2.
- But recent advances such as ResNet/GoogLeNet have challenged this paradigm
CNN (ConvNets)
CONV-ReLU-CONV-ReLU-POOL-CONV-ReLU-CONV-ReLU-POOL-CONV-ReLU-CONV-ReLU-POOL-FC

'🤖 ai logbook' 카테고리의 다른 글
| [CV] Parts-based Models & Deformable Part Model (DPM) (0) | 2023.07.29 |
|---|---|
| [CV] Object Detection & Statistical Template Approach(Dalal-Triggs Pedestrian Detector) (0) | 2023.07.19 |
| 베이즈 정리(Bayes’ theorem) & 마르코프 모델(Markov Models) (0) | 2023.07.14 |
| [NLP/자연어처리/Python] koGPT2 ChatBot 실습 (0) | 2023.07.09 |
| [NLP/자연어처리/Python] text generation 실습 (transformer 언어 번역) (0) | 2023.07.09 |
| [NLP/자연어처리/Python] text classification 실습 (0) | 2023.07.08 |
| [NLP/자연어처리] BERT & GPT & ChatGPT (0) | 2023.07.05 |
| [NLP/자연어처리] 트랜스포머(Transformer) (0) | 2023.07.04 |