
reference
Two-stage Models
Object Detection을 두 단계로 나누어 처리하는 방식으로, R-CNN, SPPNet, Fast R-CNN, Faster R-CNN등이 있다.
stage 1 : Proposal Generation Stage
이미지에서 후보 영역들을 생성한다.
이를 위해 다양한 알고리즘들이 사용될 수 있는데, R-CNN에서는 Selective Search라는 방법이, Faster R-CNN에서는 Region Proposal Network (RPN)라는 네트워크가 사용된다.
stage 2 : Classification and Bounding Box Regression Stage
후보 영역들에 대해 분류 및 bounding box의 정확한 위치를 결정하는 작업을 수행한다.
이를 위해 Convolutional Neural Network (CNN)가 사용되며,
이 과정에서 image의 해당 영역이 어떤 object를 포함하는지 분류하고, object의 위치를 더 정확하게 특정할 수 있게 된다.

R-CNN (Regions with CNN features)

R-CNN의 과정은 간단하게 input image(1)에서 검출된 region proposal(2)에 대해 CNN feature를 계산(3)하고 classify하는 것(4)이라 할 수 있다.

좀 더 자세하게 설명하면,
Image Input 후에, Region Proposal 과정을 거치게 되고 (Selective search 알고리즘을 통해 2000 여 개 정도의 region을 뽑아내어 bounding box를 생성한다), CNN 넣기전 warping 과정을 거친다.
CNN feature를 추출하고, 추출한 vecotr를 가지고 각 클래스 별로 SVM Calssifier를 학습시킨다.
SVM Calssification을 통해 확률 값을 가지게 된 bounding box에 대해 Non-Maximum Suppression을 수행하고, Bounding box Regression 과정을 거치게 된다.
단점
- region proposal algorithm에 의존적이다.
- CNN에 넣기전에 동일한 size로 warping해야 한다. 결국 image를 강제로 변형시키게 되는데, 이때image의 왜곡으로 인한 해상도 손실(정보 손실)이 발생한다.
- 여러 번 feed-forward하는 과정이 필요하다. (2000개의 Region proposal 후보를 모두 CNN에 집어넣기 때문에 training / testing 시간이 오래 걸린다)
- region proposal은 매우 느리고, CPU에서만 동작하며, 복잡한 pipeline (CNN, SVM, Bounding Box Regression 총 세 가지의 모델이 결합된 형태로 한 번에 학습이 불가능한 상황) 이 요구된다. (end-to-end 불가능)
SPPNet (Spatial Pyramid Pooling network)
R-CNN에서 CNN에 fixed input image size가 요구되는 것 (이로 인해 발생되는 crop&warp), R-CNN의 속도가 너무 느린 것을 해결하기 위해 제안된 것이 SPPNet이다.

SPPNet은 spatial pyramid pooling를 사용함으로써, 임의의 size의 image 및 여러 해상도의 image 처리가 가능하다. (나중 FC layer에서는 fixed-size input이 요구되기는 한다.)
또한, 단 한번의 CNN(single pass)로 전체 image를 한 번만 전달하면서 여러 개의 bounding box를 처리할 수 있다.
Spatial Pyramid Pooling Layer

BoW(Bag-of-Words)의 단점인 밀도만 보다 보니 전체 그림(문맥)을 고려하지 못하는 문제를 극복하기 위해 고안된 것이 Spatial Pyramid이다.
Spatial Pyramid Pooling Layer를 사용하면 피쳐 맵의 크기에 관계없이 고정 크기 피쳐를 생성할 수 있다.
SPP의 과정은 다음과 같다.
우선 마지막 pooling layer를 SPP layer(Spatial pyramid pooling layer)로 대체한다.
SPP layer의 input은 conv의 feature map이 되며(VGG라면 conv5_3), output는 특정 region of interest(RoI)에 대한 feature map이 된다.
SPP layer 안에서는 고정된 level과 size로 이루어진 feature map에 대한 피라미드가 구성되며(256-d, 4x256-d, 16x256-d),
각 피라미드에서는 각 filter의 response를 max-pool하게 되고, 이를 연결하여 fixed-length vector를 생성한다.
생성된 fixed-length vector는 fully-connected layer로 전달되게 된다.
이를 통해 다양한 크기의 input image가 네트워크에서 처리될 수 있게 된다.
장점
- image의 모든 위치에 대해 CNN을 한 번만 적용하여 feature map을 추출하고, 이를 재사용한다. 이렇게 함으로써, SPPNet은 연산량을 줄이고 처리 속도를 향상할 수 있다.
- Spatial Pyramid Pooling (SPP) layer를 도입하여, 임의의 size의 input을 받을 수 있다.
단점
- SPP pooling이 별도의 pipeline에서 이루어져 여전히 training 속도가 느리다.
- gradient가 SPP layer에서 block되어(gradient를 역전파할 수 없음. 미분이 불가능함), SPP layer 아래의 parameter들은 fine-tuning을 할 수 없다.(end-to-end 학습 불가능)
Fast R-CNN

Fast R-CNN은 R-CNN과 SPPNet에 몇 가지 개선점을 제안한 것이다.
먼저, Fast R-CNN은 SPPNet처럼 spatial pyramid pooling 개념을 활용한다.
RoI (Region of Interest) Pooling layer가 존재하는데, 이 layer는 SPP layer의 간단한 버전으로 볼 수 있다.
RoI Pooling layer를 통해 Fast R-CNN은 end-to-end 학습이 가능해졌고, 덕분에 학습 과정을 단순화하고 향상할 수 있었다.
또한, Fast R-CNN은 더 높은 mAP(mean Average Precision)을 제공하며, training 및 detection 속도가 빠르다.
(R-CNN에 비해 training은 9배, test는 213배 빠르며, SPPNet에 비해 training은 3배, test는 10배 빠르다)
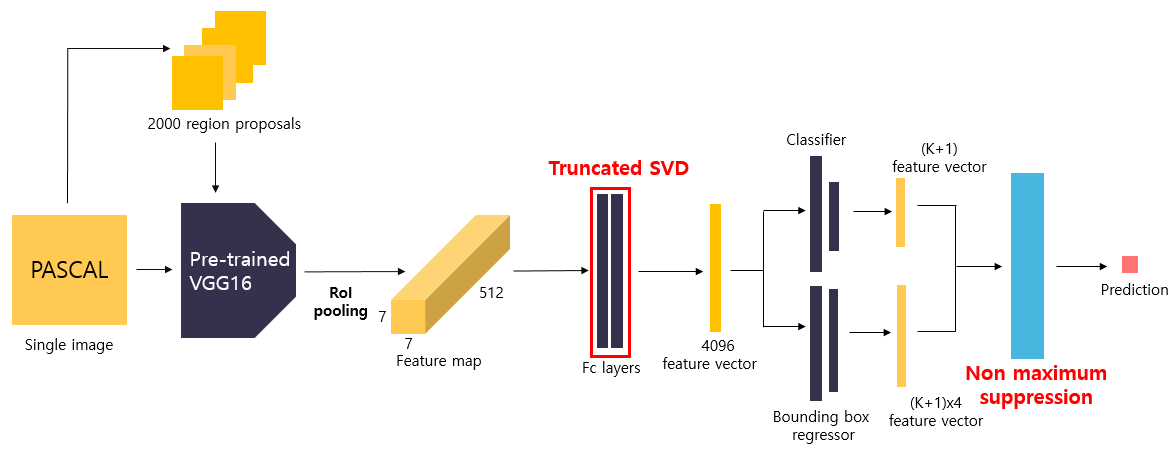
input image를 CNN(VGG16) 입력해 feature map을 추출한다.
그리고 해당 input image에 대한 RoI에 대해 Bounding box를 생성한다.
CNN(VGG16)의 마지막 max pooling layer를 RoI Pooling layer로 대체한 뒤,
이 feature map과 여러개의 RoI는 해당 ConvNet의 Input이 되고, RoI Pooling의 output으로 [R x H' x W' x 512] 차원을 출력하게 된다. (여기서 RoI Pooling Layer의 Output H', W' size는 7로 고정)
- Input : 14x14 sized 512 feature maps/bounding box, total, 2000 bounding box
- Output : 7x7x512 feature maps/bounding box, total 2000 bounding box
각 Bounding box마다 7x7x512의 feature map을 펼쳐, fc layer에 입력해 4096 size의 feature vector를 생성한다.
이렇게 얻은 4096 크기의 feature vector를 FC layer에 입력해 각 RoI마다 두 개의 output vector를 생성한다.
첫 번째 output vector는 (K+1)개의 class에 대한 Softmax 확률이며,
두 번째 output vecotr는 (K+1)개의 class에 대한 bounding box의 좌표이다. ([r,c,h,w] = (K+1)x4)
해당 output vector들로 Non maximum suppression를 진행해 최적의 bounding box만을 prediction하게 된다.
Rol Pooling Layer
RoI Pooling Layer는 pyramid level가 1인 SPP layer이다. Deep ConvNet (ex. VGG16)의 single scale에서조차 잘 동작한다.
RoI pooling layer의 동작이 미분 가능하다는 점을 이용하여, Image Classifier, Bounding box regressor, CNN을 한 번에 학습시킬 수 있다.
Rol Pooling에서의 Backpropagation은 max-pooling과 거의 같다. (Rol Pooling에서는 영역이 overlap 될 수 있다는 점이 다르다)
Fast R-CNN은 multi-task loss를 사용하여 학습을 진행한다. (classificaiton loss와 bounding box regression loss를 각각의 RoI마다 동시에 처리)
mini-batch를 구성하기 위한 계층적 샘플링을 사용한다. 만약 mini-batch가 많은 다른 training image들로부터의 RoI를 포함하면, SGD (Stochastic Gradient Descent) 단계는 비효율적일 수 있기 때문에, 소수의 image를 샘플링하고, 그다음 각 image로부터 많은 example을 샘플링한다.
이 방식의 장점은 같은 image에서 overlap되는 example 사이에서 계산을 공유할 수 있다는 것이며, 단점은 같은 image로부터의 example들의 상관관계가 있을 수 있다는 점이다. (하지만 실제로 이것이 심각한 문제가 되지는 않으며, 계산 시간을 크게 줄일 수 있다.)
장점
- single-forward로 매우 빠르다.
- multi-scale input size를 처리할 수 있다.
단점
- R-CNN보다 훨씬 빠르지만 여전히 느리다. (region proposal에 의존함에 따라)
Faster R-CNN
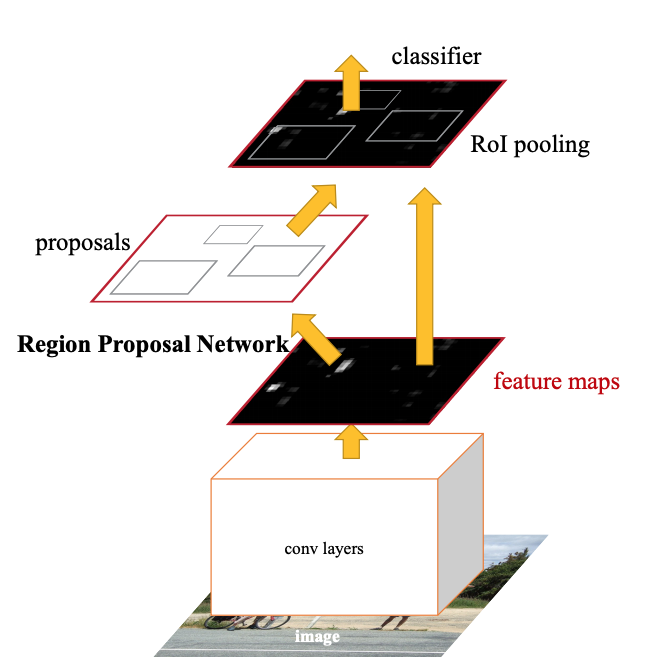
Fast R-CNN의 단점을 개선한 버전이다.
region proposal에 관한 문제를 해결하기 위해 RPN(Region Proposal Network)를 도입했다.
다른 알고리즘의 region proposal이 외부에서 진행되었으나, RPN은 network 내부에서 region proposal을 수행하게 하는 구조로 처리속도가 빨라지고, 복잡성이 줄어든다.
따라서 Faster R-CNN은 Fast R-CNN과 RPN을 결합한 모델이라고 할 수 있다.
기존의 Convolutional Network (ConvNet) 구조의 마지막 convolutional layer 바로 다음에 RPN을 추가하고,
RPN은 image 내에서 object가 있을 것 같은 영역(region proposals)를 생성한 뒤, RoI Pooling Layer로 생성된 region proposal들이 전달되게 된다.
여기서 RoI Pooling Layer는 Fast R-CNN에서 사용한 것과 동일하게 작동한다.
Region Proposal Network

CNN에 image를 입력하여 feature map을 얻는다. (HxWxp)
RPN의 input은 HxWxp인 Conv feature map가 되고 output은 WxHxk region proposal이 된다. (k는 anchor의 개수)
각각의 region proposal은 class score와 bounding box의 좌표를 가진다.
Anchor generation layer에서는 원본 image에 대한 anchor box들을 생성하는데, 예를 들어, 서로 다른 3개의 scale (128, 256, 512)과 3개의 sub-sampling ratio (2:1, 1:1, 1:2)를 사용하면, 총 9개의 anchor가 각 위치에서 생성된다.
이러한 다양한 scale과 sub-sampling ratio는 객체의 다양한 크기와 형태를 감지할 수 있게 도와준다.
Anchor target layer는 RPN이 학습하는데 사용할 수 있는 anchor를 선택하는 것이다.
일반적으로, anchor target layer는 아래와 같은 기준으로 positive(객체를 포함하고 있다고 생각되는) anchor와 negative(객체를 포함하고 있지 않다고 생각되는) anchor를 선택한다.
1. Ground truth 객체와 가장 높은 Intersection over Union (IoU)을 가진 anchor는 positive sample로 선택한다
2. IoU가 일정 임계값(예: 0.7) 이상인 anchor는 positive sample로 선택힌디
3. 반대로, 모든 ground truth 객체에 대해 IoU가 낮은 임계값(예: 0.3) 미만인 anchor는 negative sample로 선택한다
Proposal layer는 생성된 anchor boxes와 RPN에서 반환한 class scores와 bounding box regressor를 사용하여 region proposals를 추출하는 작업을 수행한다.
Proposal Target Layer의 목표는 Proposal layer에서 나온 region proposals 중에서 Fast R-CNN 모델을 학습시키기 위한 유용한 sample을 선택하는 것이다.
이때 선택된 region proposal은 맨 처음 CNN에서 출력된 feature map과 RoI pooling을 수행하게 된다.
region proposals와 ground truth box와의 IoU를 계산하여 0.5 이상일 경우 positive, 0.1~0.5 사이일 경우 negative sample로 labeling 된다.
RoI pooling 및 나머지 과정은 Fast R-CNN model의 동작 순서와 일치한다.
'🤖 ai logbook' 카테고리의 다른 글
| [RL] Actor-Critic (0) | 2023.08.10 |
|---|---|
| [RL] DQN(Deep Q-Network) - 작성중 (0) | 2023.08.08 |
| [RL] Q 러닝(Q-learning) (0) | 2023.08.07 |
| [CV] Single-stage Models (YOLO, YOLOv2/YOLO9000) (0) | 2023.07.31 |
| [CV] Parts-based Models & Deformable Part Model (DPM) (0) | 2023.07.29 |
| [CV] Object Detection & Statistical Template Approach(Dalal-Triggs Pedestrian Detector) (0) | 2023.07.19 |
| 베이즈 정리(Bayes’ theorem) & 마르코프 모델(Markov Models) (0) | 2023.07.14 |
| [NLP/자연어처리/Python] koGPT2 ChatBot 실습 (0) | 2023.07.09 |