
reference
BERT (Bidirectional Encoder Representations from Transformers)
참고 : https://arxiv.org/pdf/1810.04805.pdf
2018년에 구글이 공개한 사전 훈련된 모델
트랜스포머를 이용하여 구현하였으며, 구조자체는 transformer encoder와 거의 동일하다
(기본 구조는 transformer의 encoder를 쌓아올린 구조)
Pre-training
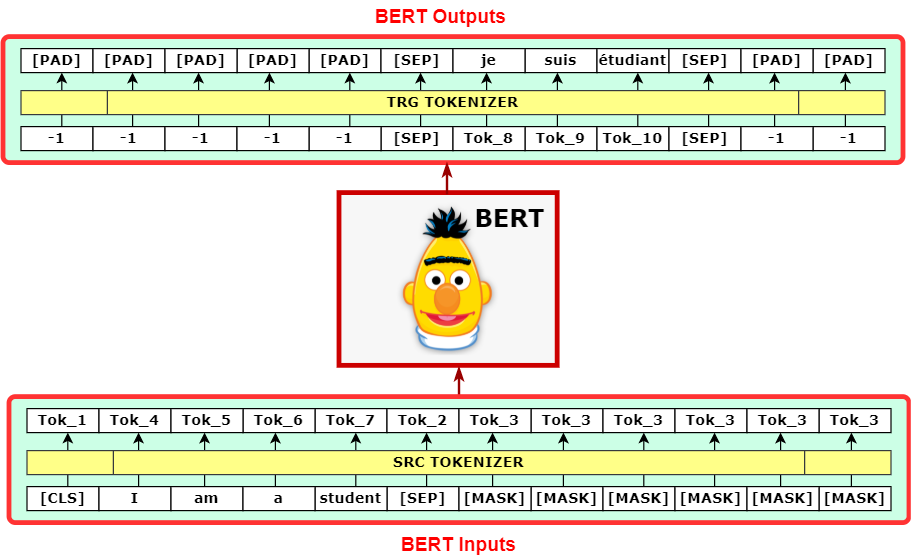
Bert는 위키피디아(25억 단어)와 BooksCorpus(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련을 진행했다.
여기에서 Masked Language Model (MLM)과 Next Sentence Prediction (NSP) 두 가지의 pre-training tasks를 수행하는데,
MLM은 입력 문장에서 랜덤하게 선택된 단어를 마스킹하고 이를 예측하는 과정이고,
NSP는 두 문장이 주어졌을 때 두 번째 문장이 첫 번째 문장의 바로 다음에 오는 문장인지 아닌지를 예측하는 과정이다.
Segment Embedding(Training Input)
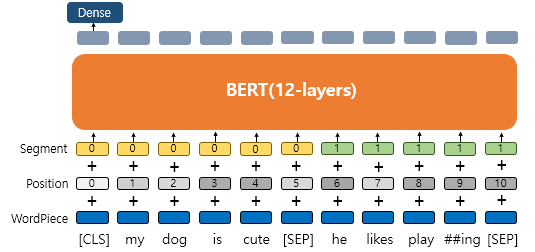
문장 구분을 위해서 BERT는 세그먼트 임베딩이라는 또 다른 임베딩 층(Embedding layer)을 사용한다.
Input = elementwise-sum(position + segment + token)
* [CLS] token : 문장 분류를 위한 특수한 토큰
특수 토큰[CLS]의 final state에서 모델은 두 문장이 연속적인 문장인지의 여부를 예측한다.
- WordPiece Embedding : 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개.
- Position Embedding : 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개.
- Segment Embedding : 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
MLM (Masked LM, Masked Language Model)
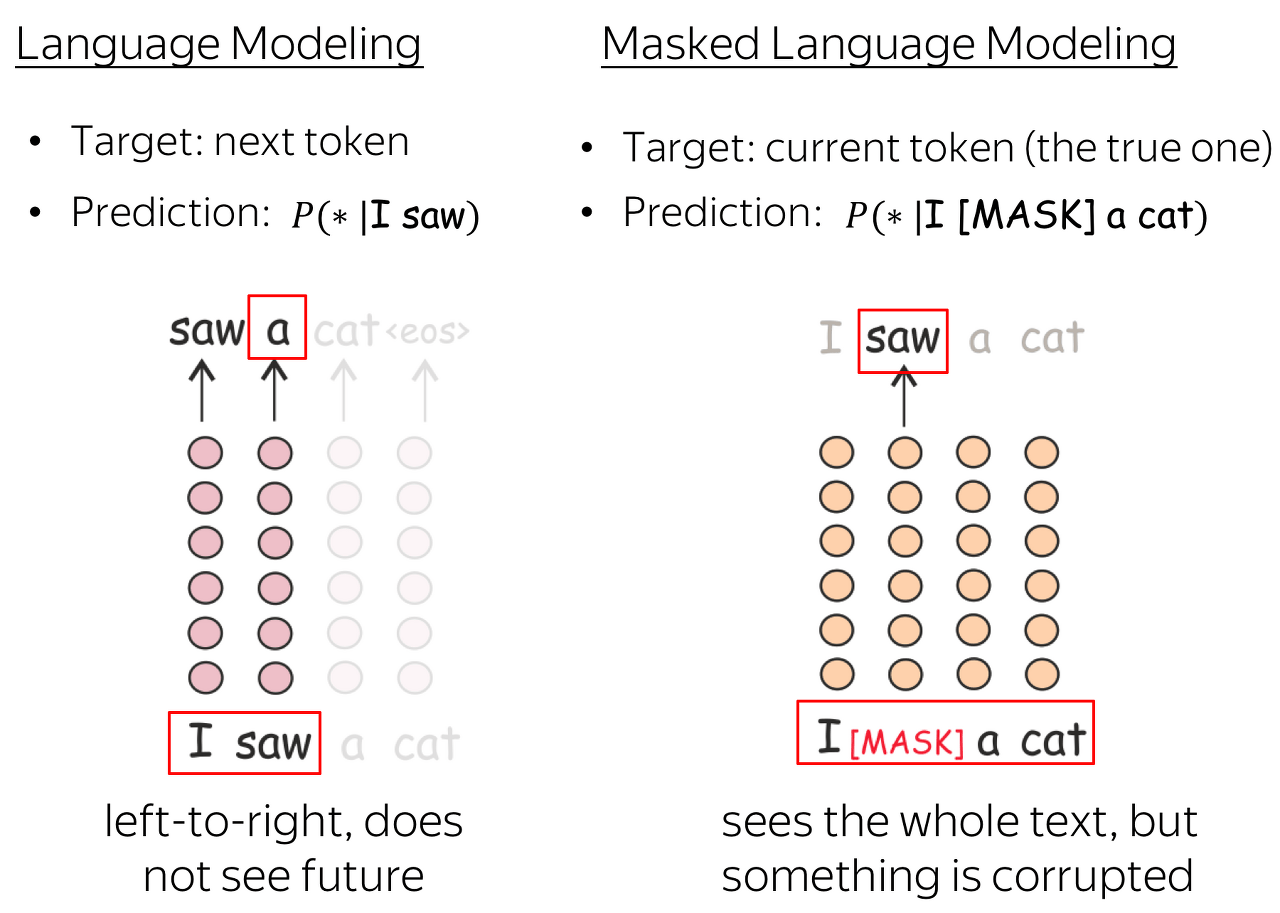
임의로 몇 개의 토큰을 mask하고, mask 된 토큰을 예측하는 것
이러한 방식은 기존의 left-to-right 구조와는 다르게 양쪽 문맥을 모두 학습할 수 있도록 한다 (양방향성)
(표준 left-to-right LM은 이전 토큰을 기반으로 다음 토큰을 예측했었음. )
과정
- 80%의 단어들은 [MASK]로 변경한다.
Ex) The man went to the store → The man went to the [MASK] - 10%의 단어들은 랜덤으로 단어가 변경된다.
Ex) The man went to the store → The man went to the dog - 10%의 단어들은 동일하게 둔다.
Ex) The man went to the store → The man went to the store
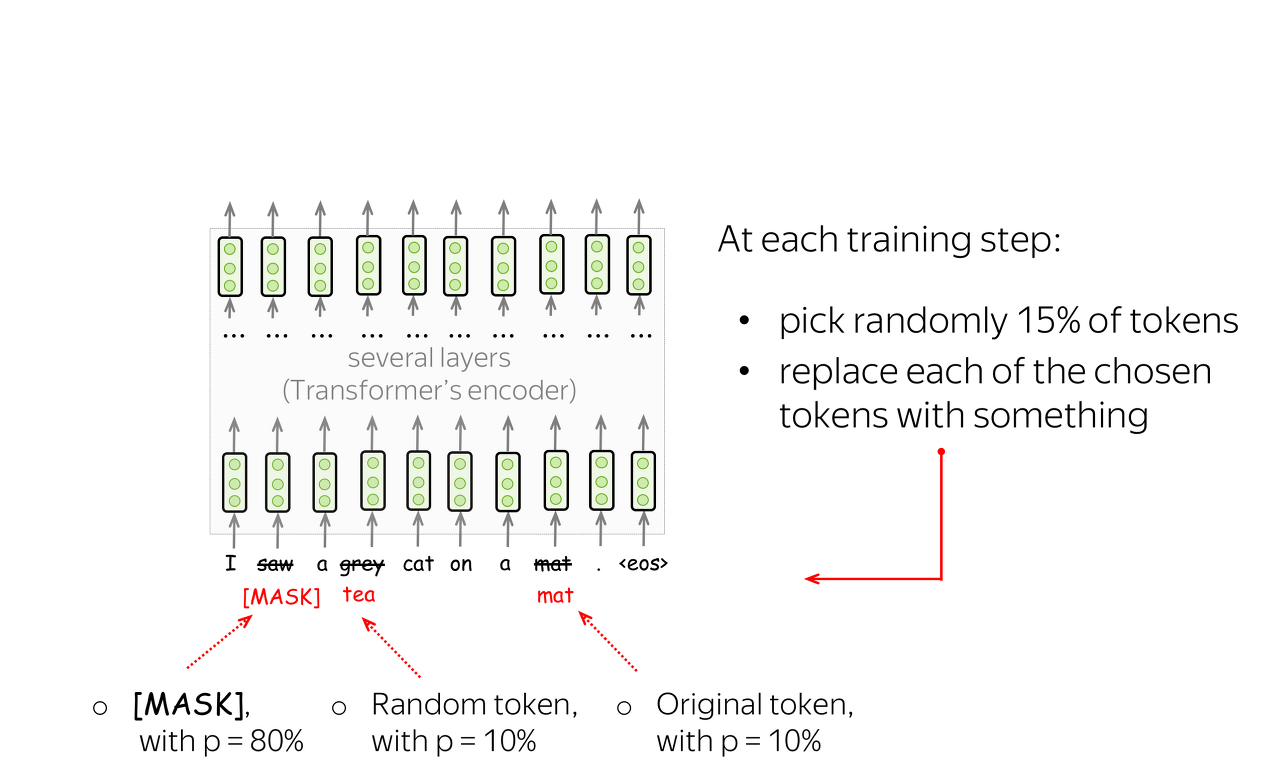
[MASK]만 사용할 경우에는 [MASK] 토큰이 fine-tuning 단계에서는 나타나지 않으므로, pre-training 단계와 fine-tuning 단계에서의 불일치가 발생하는 문제가 있다. 이 문제을 완화하기 위해서 랜덤으로 선택된 15%의 단어들의 모든 토큰을 [MASK]로 사용하지 않는다.
Next Sentence Prediction (NSP)
두 문장이 일부 텍스트에서 연속적인 문장인지를 예측하는 방식으로 훈련하는 것
- 이어지는 문장의 경우
Sentence A : The man went to the store.
Sentence B : He bought a gallon of milk.
Label = IsNextSentence - 이어지는 문장이 아닌 경우 경우
Sentence A : The man went to the store.
Sentence B : dogs are so cute.
Label = NotNextSentence
Fine-tuning
파라미터 재조정을 위한 추가 훈련 과정이다.
(사전 학습 된 BERT에 우리가 풀고자 하는 태스크의 데이터를 추가로 학습 시켜서 테스트하는 단계)
이때 사용되는 데이터셋은 라벨이 있는 데이터셋이다.
Sequence-level의 classification tasks
Single sentence classification
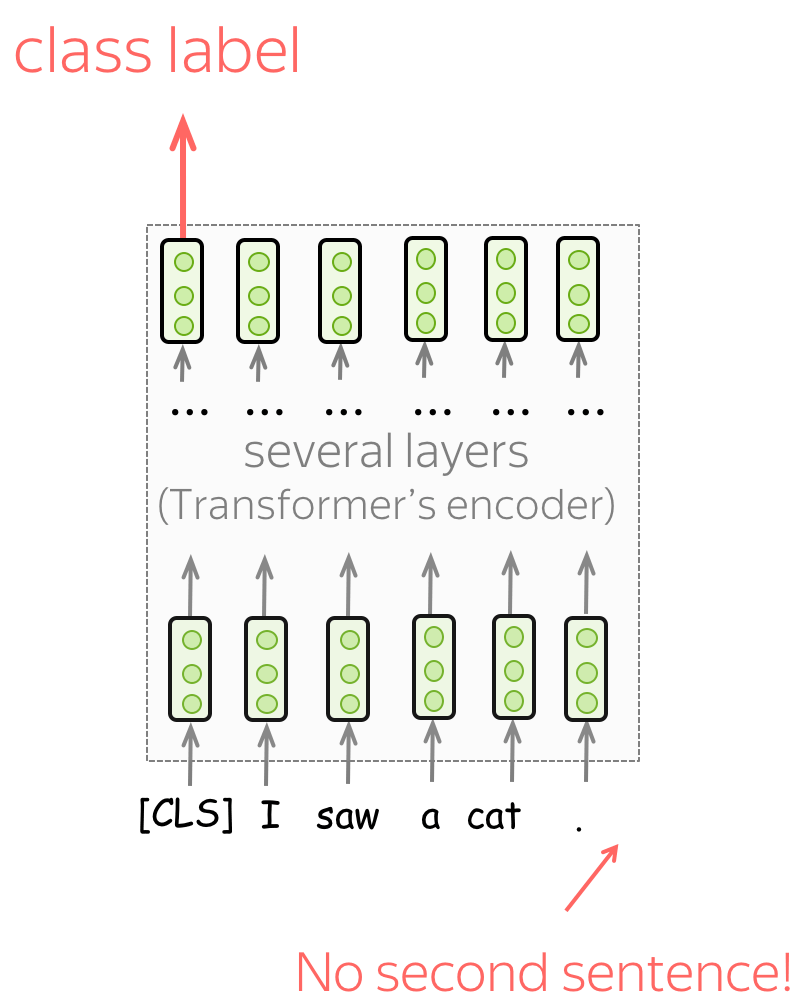
[CLS] 토큰의 최종 표현에서 레이블을 예측한다.
텍스트 분류 문제를 해결하기 위해, [CLS] 토큰의 위치의 출력층에 밀집층(Dense layer) 또는완전 연결층(fully-connected layer)을 추가하여 분류 예측을 진행한다.
Sentence Pair Classification
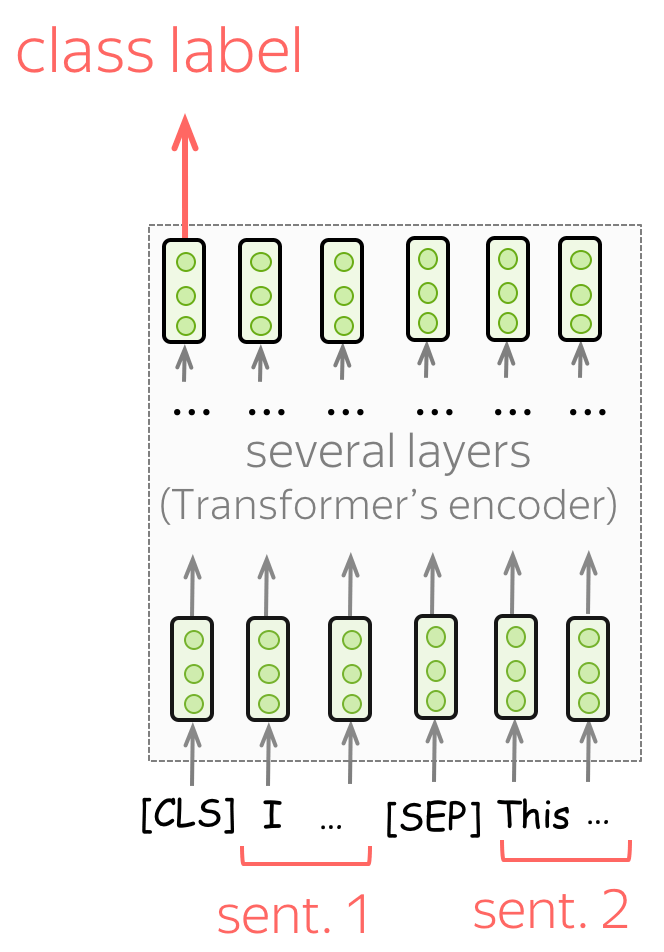
입력 텍스트가 여러 개이므로, 텍스트 사이에 [SEP] 토큰을 집어넣고, 두 종류의 세그먼트 임베딩(Sentence0, Sentence1)을 사용하여 Document를 구분한다.
Single sentence classification와 유사하게 [CLS] 토큰의 최종 표현에서 분류 예측을 진행한다.
Token-level classificationt tasks
Question Answering
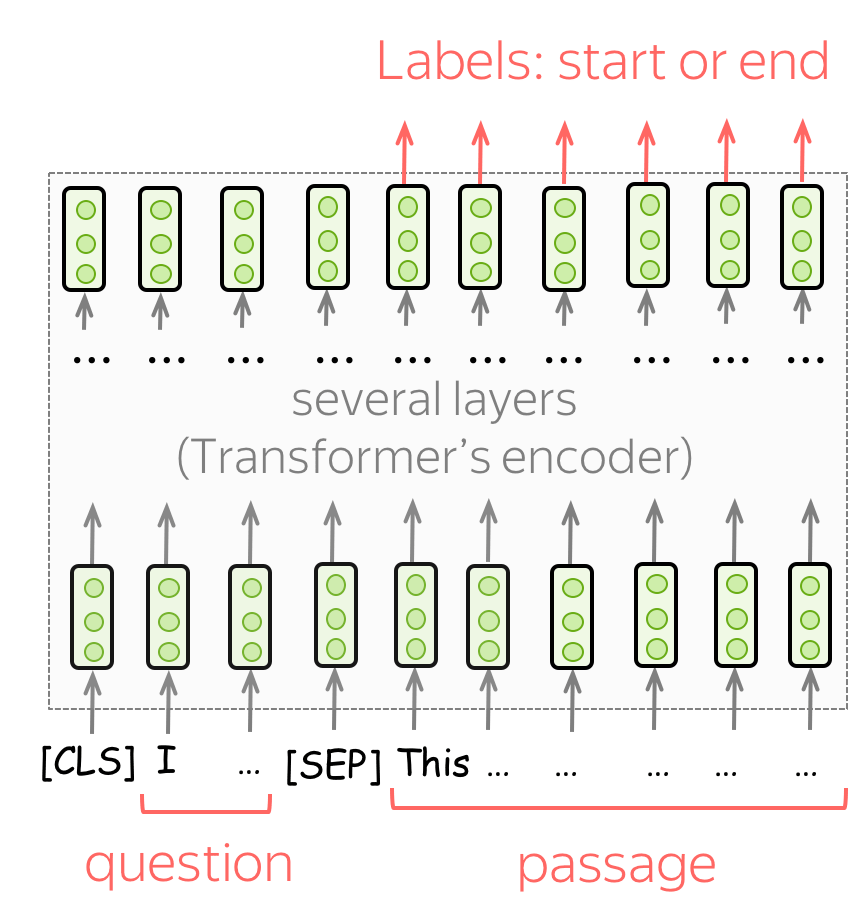
Question과 Passage라는 두 개의 텍스트 쌍을 입력한다.
해당 Question에 대한 Answer은 항상 Passage의 일부이며, Passage에서 Answer이 위치한 정확한 부분을 찾는 것이 목표이다.
(Question과 Passage을 입력받으면, Passage의 일부분을 추출해서 Question에 답변)
Passage의 각 토큰에 대해 최종 BERT 표현을 사용하여 이 토큰이 올바른 세그먼트의 시작인지 끝인지 예측한다.
Single sentence tagging
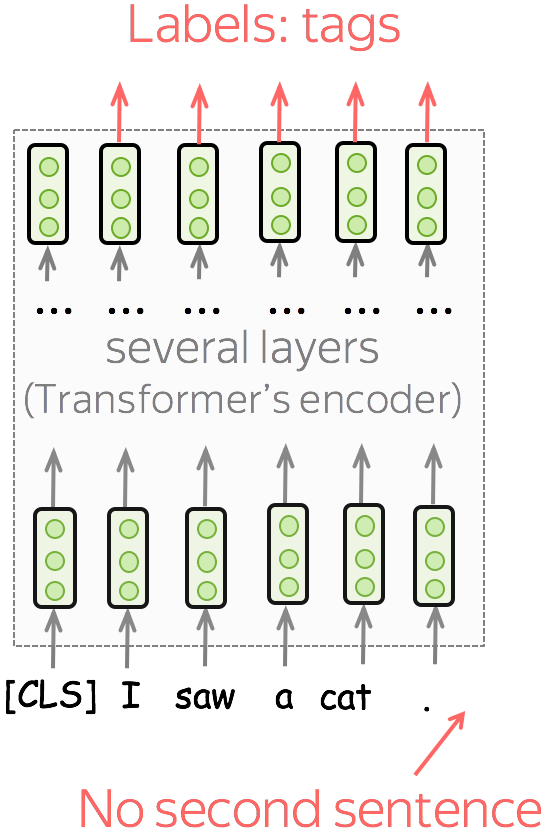
각 토큰에 대한 태그의 예측을 진행한다.
GPT
Bert와 마찬가지로 Transformer의 Decoder 구조를 그대로 가져온 모델이다.
pre-training과 fine-tuning을 도입한 첫번째 모델이다.
단점으로는 uni-direction 모델이라는 점에 있는데, 실제로 Bert와 비교했을 때 (Bert는 bi-direction를 고려한 모델임) GPT-1이 Bert보다 성능이 좋지 않음을 보였다.
➡ GPT-2부터는 모델의 목표를 변경하였다. GPT-2(GPT-3)는 언어의 Generation을 위한 모델이고, Bert는 언어의 Understanding을 위한 모델이기에 더 이상의 비교는 무의미할 수 있다.

Pre-training
Autoregressive language model (next word prediction)
이전 context를 사용하여 next word를 예측하도록 학습한다.
(Bert는 masked language model + next sentence prediction을 사용했다)
Fine-tuning
GPT 모델의 목적은 언어 모델을 개선하는 것에 있다.
이를 위해, 크고 다양한 corpus와 model size를 사용하여 학습을 진행한다.
Few-shot setting

- Zero-Shot : 데모가 없고 자연어로만 지시를 제공
- One-Shot : 하나의 데모만 허용
- Few-Shot (또는 in-context) : 여러 개의 데모 (일반적으로 10개에서 100개)를 허용
GPT 모델은 unsupervised learning tasks(비지도 학습 작업)에 적용되면서, few-short behavior에 집중하게 되었다.
모델의 용량이 커짐에 따라 모델이 in-context 예제에서 패턴을 인식하는 능력이 증가함을 밝혀냈고, 제공되는 데모의 수가 증가함에 따라 모델은 더 많은 context를 학습하여 예측 정확도를 향상시킬 수 있다.
따라서 더이상 gradient update나 fine-tuning이 필요하지 않게 된다.
(GPT-2와 GPT-3 부터는 few-shot setting으로 fine-tuning 없이도 좋은 성능을 낼 수 있다. -> Generation에 집중하기로 결정)
ChatGPT
chatGPT는 사용자의 의도와 모델의 출력을 일치시키기 위하여 Human Feedback(RLHF)를 학습과정에 포함하는 새로운 접근 방식을 도입하였다.
GPT-3 모델을 초기 모델로 사용하였고, Supervised Fine-Tuning(SFT)와 Reinforcement Learning from Human Feedback (RLHF)을 적용하는 과정을 거치게 된다.
Supervised Fine-Tuning (SFT)
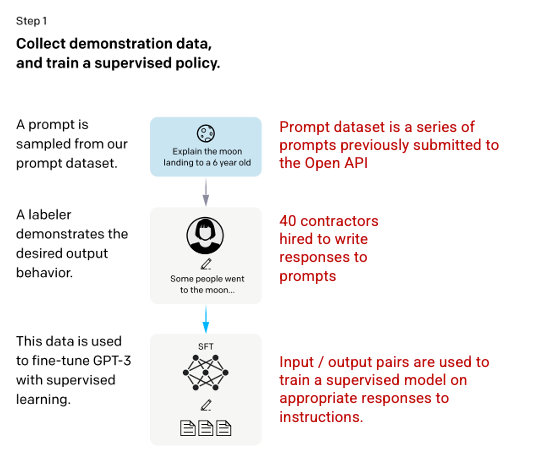
우선, SFT 모델을 개발하기 위해 실제 사람을 계약한다.
입력 prompt에서는 OpenAI API에 실제 사용자가 입력한 내용을 수집하였으며, 40명의 고용된 Labeler들은 해당 prompt의 답변을 직접 입력하여(다양한 경우에 대한) 각 입력에 대한 출력을 만들게 된다. 그리고 이를 통해 demonstration dataset을 생성한다.
Reinforcement Learning from Human Feedback (RLHF)
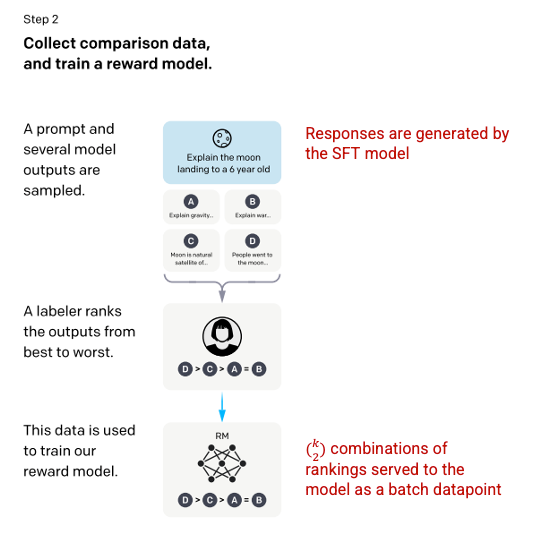
Reward Model은 Step1에서 진행한 SFT 모델을 업데이트하기 위해 사용된다.
Labeler들은 prompt에 대한 SFT 모델 출력들에 대해 순위를 매기도록 요청받게 되는데, 이는 Reward Model을 학습시키는데 사용된다.
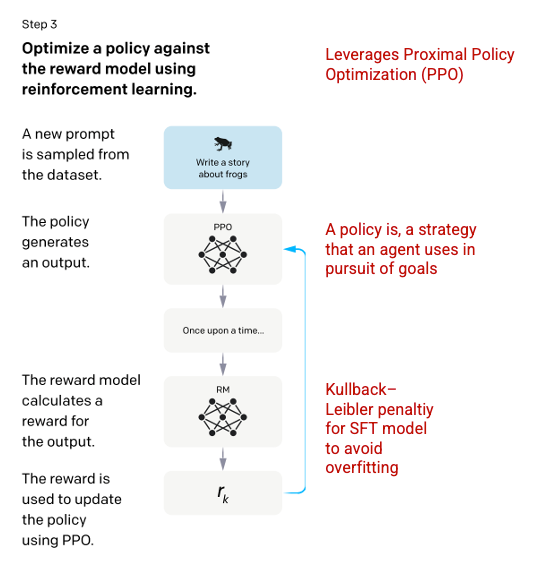
그리고, Model은 random prompt(new prompt) 제시 받고, Step2에서 Model이 학습한 'Policy'에 의해 ouput 결과를 생성하게 된다.
Step2에서 개발된 Reward Model을 기반으로, Prompt와 Output에 대한 Scaler Reward Value가 결정되게 되고,
이 Reward는 Model로 다시 feedback되어 Policy가 강화되게 된다.
(이때 PPO(Proximal Policy Optimization) 알고리즘을 사용한다.)
'🤖 ai logbook' 카테고리의 다른 글
| [NLP/자연어처리/Python] koGPT2 ChatBot 실습 (0) | 2023.07.09 |
|---|---|
| [cs231n/Spring 2023] Lecture 5: Image Classification with CNNs (0) | 2023.07.09 |
| [NLP/자연어처리/Python] text generation 실습 (transformer 언어 번역) (0) | 2023.07.09 |
| [NLP/자연어처리/Python] text classification 실습 (0) | 2023.07.08 |
| [NLP/자연어처리] 트랜스포머(Transformer) (0) | 2023.07.04 |
| [NLP/자연어처리] seq2seq 인코더-디코더 및 어텐션 모델 (Seq2Seq Encoder-Decoder & Attention Model) (0) | 2023.07.04 |
| [NLP/자연어처리] 자연어 처리에서의 순환 신경망 (RNN in Natural Language Processing) (0) | 2023.07.01 |
| [cs231n/Spring 2023] Lecture 4: Neural Networks and Backpropagation (0) | 2023.07.01 |