
reference

Transformer
참고 : "Attention is all you need", https://arxiv.org/pdf/1706.03762.pdf
2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델로, 번역 성능에서 RNN보다 우수한 성능을 보여줌
seq2seq처럼 인코더-디코더 구조를 따르긴 했지만, attention만으로 구현한 모델
* attention : 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고하는 것
* seq2seq : seq2seq도 attention을 사용하긴 했으나, RNN의 보정을 위한 용도로만 사용하였음
자세히 다루기 전에, RNN과의 비교
RNN vs Transformer
RNN : vanishing gradient 문제 존재. (LSTM으로 개선하여 줄이긴 했으나 여전히 vanishing gradient 문제 존재), 하지만 sequence length의 제한이 없음.
Transformer : 한번의 연산으로도 모든 정보를 embedding 할 수 있음(계산량은 많으나 정확함). 하지만 sequence length의 제한이 존재함

Positional Encoding
RNN이 자연어 처리에서 유용했던 이유는 각 단어의 위치 정보(position information)를 가질 수 있다는 점에 있었다.
하지만 트랜스포머는 단어 입력을 순차적으로 받는 방식이 아니다.
따라서, 트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하게 되는데, 이를 포지셔널 인코딩(positional encoding)이라고 한다.
$$PE_{(pos,\ 2i)}=sin(pos/10000^{2i/d_{model}})$$
$$PE_{(pos,\ 2i+1)}=cos(pos/10000^{2i/d_{model}})$$
위와 같은 포지셔널 인코딩 방법을 사용하면 순서 정보가 보존되는데, 예를 들어 각 임베딩 벡터에 포지셔널 인코딩의 값을 더하면 같은 단어라고 하더라도 문장 내의 위치에 따라서 트랜스포머의 입력으로 들어가는 임베딩 벡터의 값이 달라진다. 이에 따라 트랜스포머의 입력은 순서 정보가 고려된 임베딩 벡터가 된다.
→ 왜 $10000^{2i/d_{model}}$ 로 나누는가? 0~1 사이의 실수값이 나오도록 하기 위하여

Encoder

Transformer의 Encoder는 N개의 동일한 레이어로 구성되어 있다.
각 레이어에는 두 개의 sublayer가 존재하며,
첫 번째 sublayer는 Multi-Head Self-attention이고,
두 번째 sublayer는 Position-wise Feed Forward Network이다.
그리고 각 sublayer 사이에 Add & Norm 과정을 진행하는 것을 볼 수 있는데,
이 때의 Add & Norm은 residual connection & layer normalization를 의미한다.

$$\hat{x}_{i, k} = \frac{x_{i, k}-μ_{i}}{\sqrt{σ^{2}_{i}+\epsilon}}$$
i : batch-dim
k : feature-dim

각 sublayer의 출력은 Add & Norm에 의해 $LN = LayerNorm(x + sublayer(x))$ 로 계산된다.
여기서 x는 이전 레이어의 출력을 의미한다.
또한, 여기서 사용되는 모든 Querys, keys, Values는 이전 layer의 출력으로부터 나온다.
Multi-Head Attention
Self-Attention (Scaled Dot-product Attention)
단어 사이 관련성을 구하는 것

seq2seq에서의 attention은 다음과 같았다.
Q = Query : t 시점의 디코더 셀에서의 은닉 상태
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
하지만, transformer에서의 attention은 다음과 같다.
Q : 입력 문장의 모든 단어 벡터들
K : 입력 문장의 모든 단어 벡터들
V : 입력 문장의 모든 단어 벡터들
즉, Q=K=V

각 단어 벡터마다 일일히 가중치 행렬을 곱하는 것이 아니라 문장 행렬에 가중치 행렬을 곱하여 Q행렬, K행렬, V행렬을 구한 뒤,
각 단어간의 유사도 점수 (*Attention Score)를 계산하기 위해 Q와 K의 내적을 계산해 준 뒤,
Attention Score가 너무 커지는 것을 방지하기 위해 k0dimension의 제곱근으로 나눠준다.
(이를 Scaled Dot-Product라고 부른다)

$$Attention(Q, K, V) = softmax({QK^T\over{\sqrt{d_k}}})V$$
여기에서, input dimension = output dimension
Multi-Head Attention
여러번의 어텐션을 병렬로 사용하는 것.
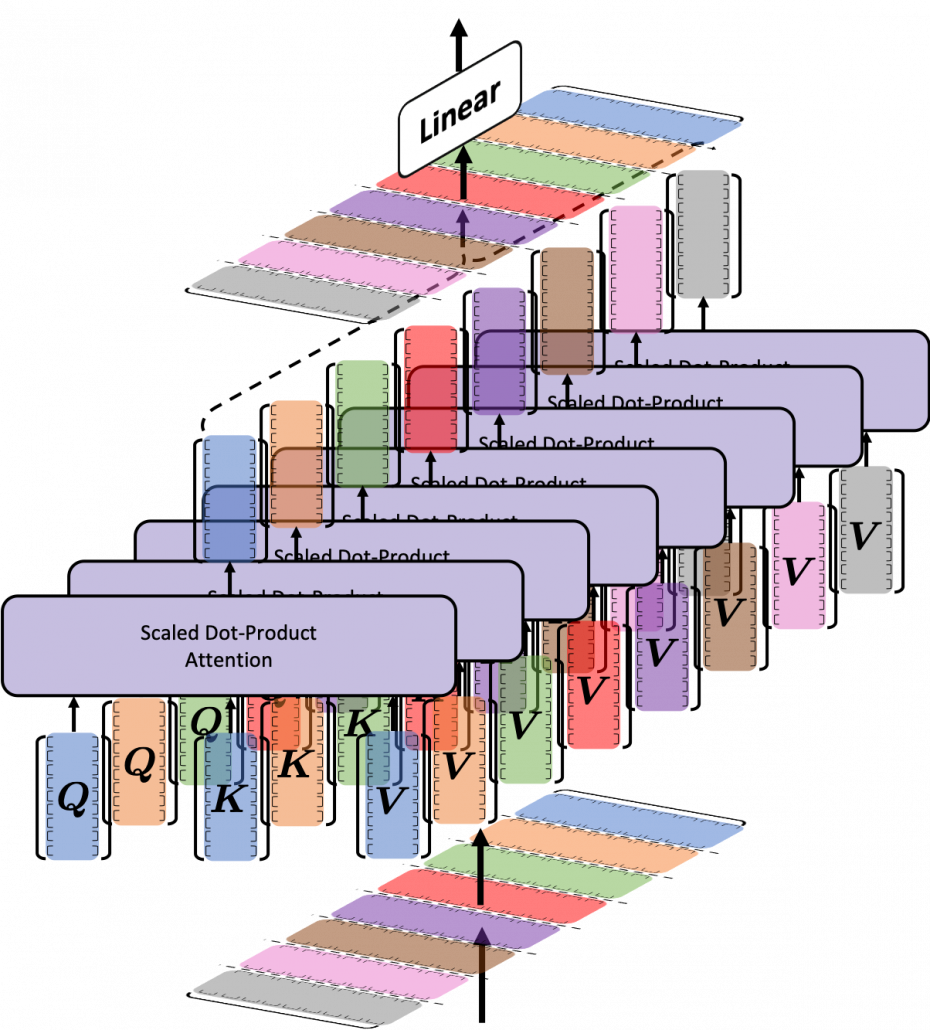
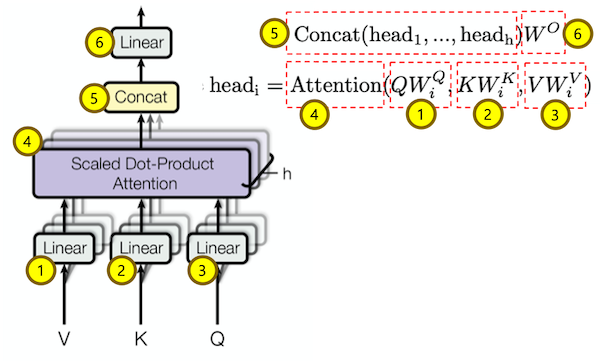
$$MultiHead(Q, K, V) = Concat(head_1,...,head_h)W^O$$
$$head_i = Attention(Q{W_i}^Q, K{W_i}^K, V{W_i}^V)$$
Position-wise Feed Forward Network
인코더와 디코더에서 공통적으로 가지고 있는 sublayer로 쉽게 말하면 Fully-connected FFNN로 해석할 수 있음
입력 시퀀스의 특징을 추출하고, 이를 바탕으로 더 정확한 예측을 할 수 있도록 도와주는 역할
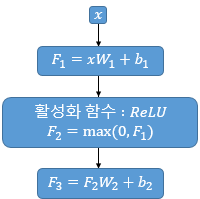
$$FFNN(x) = MAX(0, x{W_{1}} + b_{1}){W_2} + b_2$$
두 개의 linear transformation과 ReLU 활성화 함수로 구성된다.
Encoder는 총 num_layers만큼의 층 연산을 순차적으로 한 후에 마지막 층의 Encoder의 출력을 Decoder에게 전달한다.
Decoder

Decoder는 Encoder와 거의 유사한 구조를 가지고 있다.
Decoder는 Encoder와 동일한 N개의 동일한 레이어로 구성되어 있으며,
각 레이어에는 세 개의 sublayer가 존재한다.
첫 번째 sublayer는 Multi-Head Self-attention이고,
두 번째 sublayer는 Multi-Head Attention (from encoder to decoder)이고,
세 번째 sublayer는 Position-wise Feed Forward Network이다.
Multi-Head Self-Attention & look-ahead mask
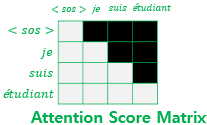
Decoder의 Multi-Head Self-attention는 Encoder와 비교해 attention score matrix에 masking을 적용한다 (이를 통해 자기 자신과 그 이전 단어들만을 참고할 수 있게 된다) 는 점을 제외하면 Encoder의 Multi-Head Self-attention와 동일한 연산을 수행한다
Multi-Head Attention (from encoder to decoder)
Encoder Stack의 출력에 대한 Attention을 수행하여, 입력 시퀀스의 정보를 추출하고, 이를 Decoder에 전달하는 역할

인코더의 첫번째 서브층 : Query = Key = Value -> Self-Attention
디코더의 첫번째 서브층 : Query = Key = Value -> Self-Attention
디코더의 두번째 서브층 : Query : 디코더 행렬 / Key = Value : 인코더 행렬 -> Q, K, V가 다르기 때문에, Self-Attention이 아님!
'🤖 ai logbook' 카테고리의 다른 글
| [cs231n/Spring 2023] Lecture 5: Image Classification with CNNs (0) | 2023.07.09 |
|---|---|
| [NLP/자연어처리/Python] text generation 실습 (transformer 언어 번역) (0) | 2023.07.09 |
| [NLP/자연어처리/Python] text classification 실습 (0) | 2023.07.08 |
| [NLP/자연어처리] BERT & GPT & ChatGPT (0) | 2023.07.05 |
| [NLP/자연어처리] seq2seq 인코더-디코더 및 어텐션 모델 (Seq2Seq Encoder-Decoder & Attention Model) (0) | 2023.07.04 |
| [NLP/자연어처리] 자연어 처리에서의 순환 신경망 (RNN in Natural Language Processing) (0) | 2023.07.01 |
| [cs231n/Spring 2023] Lecture 4: Neural Networks and Backpropagation (0) | 2023.07.01 |
| [NLP/자연어처리] 정보 검색 & 단어 임베딩(Information Retrieval & Word Embedding) (0) | 2023.07.01 |