
reference
https://wikidocs.net/book/5942
https://wikidocs.net/book/7888
Actor-Critic
강화학습에서 REINFORCE(Policy Gradient 방법)는 CartPole(균형을 잡는 문제)와 같은 간단한 예제에서는 효과적이나, 더 복잡한 환경의 적용은 어렵다.
DQN(deep Q-networks)은 이산적인 행동 공간에서 특히 유용하지만, epsilon-greedy와 같은 추가적인 정책 기능이 필요한 문제가 있다.
이런 두 기법의 장점을 합친 것이 Actor-Critic 알고리즘으로, 다양한 영역에서 뛰어난 결과를 보여주고 있다.
Actor-Critic은 강화학습의 한 방법론으로, 에이전트가 주어진 환경에서 최적의 행동을 학습하는 데 사용된다.
이 알고리즘은 동시에 정책과 가치함수를 학습하게 된다.
- Actor
이는 에이전트의 행동을 결정하는 정책 함수를 학습하는 부분. 주어진 상태를 기반으로 가능한 행동의 확률 분포를 출력하고, 이를 통해 행동을 결정한다. - Critic
Critic은 현재 상태에 대한 기대 보상, 즉 가치함수를 학습하는 역할. 에이전트의 선택한 행동의 가치를 평가하고, 그 결과를 바탕으로 가치를 갱신한다.
Actor-Critic algorithm
Actor-Critic 알고리즘에서 Actor는 주어진 정책을 따르는 동안 샘플을 수집하고,
이 샘플들을 기반으로 정책을 업데이트한다.
샘플 $ (s^{i}_t, a^{i}t, s^{i}{t+1}, r^{i}_t) $가 주어졌을 때 $\theta$를 업데이트하려면,
먼저, $v^{\pi}{\phi}$를 회귀 문제(regression problem)를 통해 학습하거나 근사한다.
$ \min{\phi} L(\phi) := \frac{1}{2} \sum_i \Vert v^{\pi}_{\phi}(s_i) - y_i \Vert^2 $
그리고 TD 오류 계산 (Critic에 의해 제공) 을 진행한다.
$ \delta^i_t = r^{i}_{t} + \gamma v^{\pi}{\phi}(s^{i}_{t+1}) - v^{\pi}{\phi}(s^{i}_{t}) $
$\gamma$ : 할인율
$v^{\pi}{\phi}$ : Critic의 가치 추정
Actor의 정책은 주어진 TD 오류를 기반으로 그래디언트 상승 방향으로 업데이트된다.
정책의 파라미터 $\theta$에 대한 업데이트는 다음과 같다.
$ \nabla_\theta J(\theta) = \nabla_\theta \log \pi_\theta(a^{i}_{t}|s^{i}_{t}) \cdot \delta^{i}_{t} $
이 공식은 정책의 로그 그래디언트에 TD 오류를 곱하여 정책 파라미터 $\theta$를 업데이트하는 방법을 나타낸다.
일반적으로, 학습률 $\alpha$도 사용하여 업데이트 스텝 크기를 조절한다.
$ \theta \leftarrow \theta + \alpha \nabla_\theta J(\theta) $
여기서 중요한 점은 Critic의 가치 함수 $v^{\pi}{\phi}$가 얼마나 정확하냐에 따라,
Actor의 업데이트의 효과도 달라진다는 것이다.
Online Actor-Critic algorithm
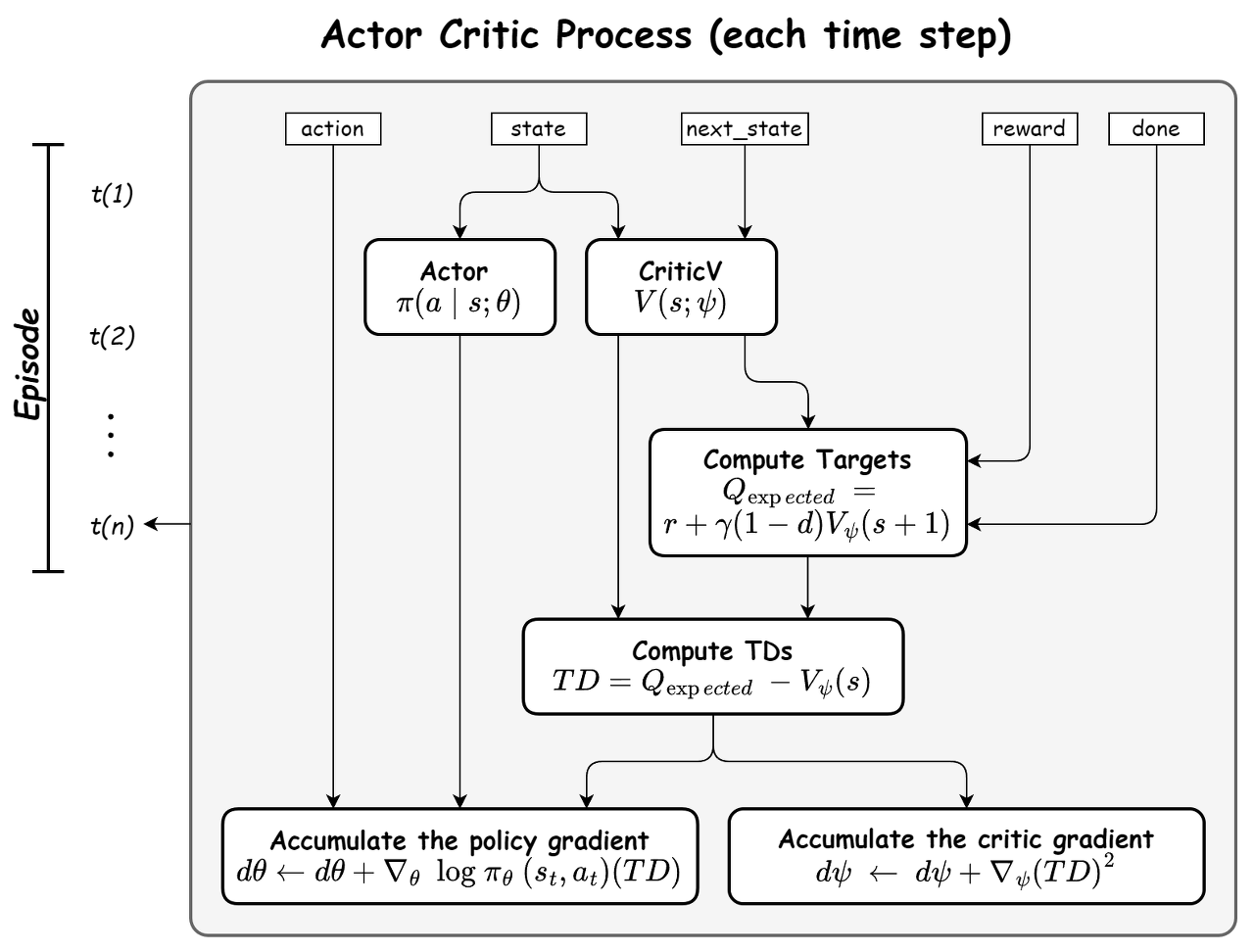
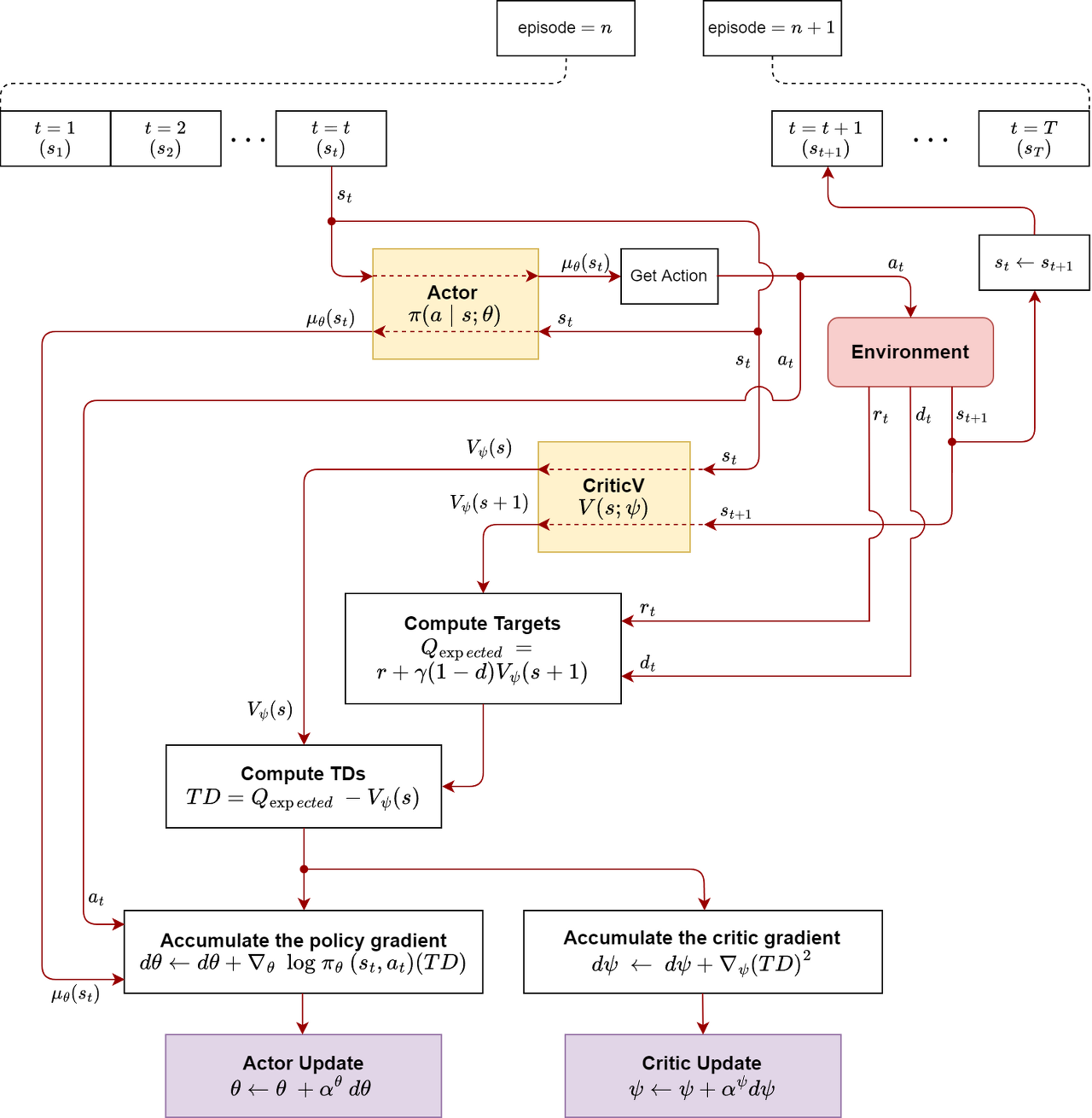
Online Actor-Critic 알고리즘은 Actor-Critic의 한 변형으로,
전체적인 구조는 기본 Actor-Critic과 유사하지만, 데이터를 온라인(즉, 순차적으로 혹은 실시간으로)으로 수집하고 처리한다는 점이 다르다.
[Diagram : Actor, CriticV]
먼저, 현재의 정책 $\pi_{\theta}(a|s)$을 사용해, 환경과 상호작용하여 샘플을 하나씩 수집한다.
(배치를 기다리지 않고, 즉시 학습에 사용될 수 있는 샘플을 얻을 수 있다.)
$(s^{i}_t, a^{i}t, s^{i}{t+1}, r^{i}_t)$
[Diagram : Compute Targets]
여기서 타겟은 주어진 보상과 다음 상태의 가치 함수의 할인된 합으로 계산된다.
$y_t = r_t + \gamma v^{\pi}_{\phi}(s_{t+1}) $
[Diagram : Compute TDs]
그리고, 각 샘플마다 TD 오류를 계산한다.
$ \delta_t = r_t + \gamma v^{\pi}_{\phi}(s_{t+1}) - v^{\pi}_{\phi}(s_t) $
[Diagram : Accumulate the critic gradient]
상태 가치 함수 $v^{\pi}_{\phi}(s)$를 TD 오류를 사용하여 업데이트한다. (Critic 업데이트 과정)
$ \phi \leftarrow \phi + \alpha_{\phi} \delta_t \nabla_{\phi} v^{\pi}_{\phi}(s_t) $
$\alpha_{\phi}$ : Critic의 학습률
[Diagram : Accumulate the policy gradient]
$\pi_{\theta}(a|s)$를 TD 오류를 사용해 업데이트한다.
$ \theta \leftarrow \theta + \alpha_{\theta} \delta_t \nabla_{\theta} \log \pi_{\theta}(a_t|s_t) $
$\alpha_{θ}$ : Actor의 학습률
이렇게 Online Actor-Critic은 환경으로부터 즉시 피드백을 받아 학습을 수행하므로, 변화하는 환경 조건에 빠르게 대응할 수 있다.
장점
Critic 덕분에 낮은 분산을 갖는다. 따라서 바이어스와 분산의 균형을 찾을 수 있다.
Actor-Critic 방법은 다른 강화 학습 알고리즘에 비해 보다 빠르게 수렴할 수 있다. (학습이 효율적으로 이루어진다)
단점
두 가지 다른 네트워크 (Actor와 Critic)를 동시에 학습해야하기 때문에 구현이 다소 복잡해질 수 있다.
Critic의 가치 추정 오류가 Actor의 학습에 영향을 미칠 수 있다. 즉, Critic이 잘못된 정보를 제공하면 Actor도 잘못된 방향으로 업데이트될 수 있다.
'🤖 ai logbook' 카테고리의 다른 글
| [RL] 강화 학습(Reinforcement Learning) (0) | 2024.06.23 |
|---|---|
| [RL] 간단한 OpenAI Gym 튜토리얼 (CartPole) (0) | 2023.08.28 |
| [RL] Deep Deterministic Policy Gradient (DDPG) (0) | 2023.08.21 |
| [paper] ChatDev - 소프트웨어 개발을 위한 통신 에이전트(Communicative Agents for Software Development) (0) | 2023.08.16 |
| [RL] DQN(Deep Q-Network) - 작성중 (0) | 2023.08.08 |
| [RL] Q 러닝(Q-learning) (0) | 2023.08.07 |
| [CV] Single-stage Models (YOLO, YOLOv2/YOLO9000) (0) | 2023.07.31 |
| [CV] Two-stage Models (R-CNN, SPPNet, Fast R-CNN, Faster R-CNN) (0) | 2023.07.29 |