
reference
Seq2Seq Encoder-Decoder
seq2seq는 transformer의 기본 구조로 번역기 등에 사용되는 대표적인 모델이다.
주로 LSTM(Long-Short Term Memory)를 사용하며, 인코더와 디코더로 구성된다.
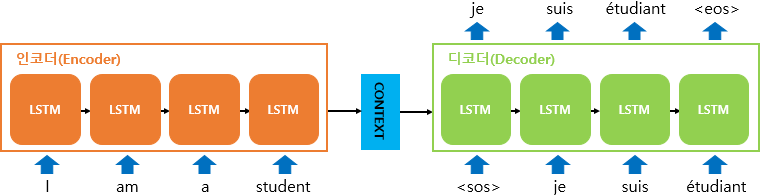
Encoder
입력 문장을 토큰화한 뒤에 구해진 word sequence로부터 sentence representation(encoded vector/context vector)를 생성한다.
Decoder
Encoder가 생성한 sentence representation(encoded vector/context vector)를 사용해 출력 시퀀스를 생성한다. RNN 구조를 사용하여 각 스텝마다 다음에 등장할 확률이 높은 단어를 예측하면서 출력 시퀀스를 구성합니다.
Attention Model
위에서 설명한 seq2seq 모델에는 크게 2가지 문제가 있다.
1. 입력 시퀀스가 길어질 수록 인코더가 모든 정보를 하나의 고정된 크기의 벡터(은닉 상태)에 압축하는 것이 어려워진다. ➡ 정보 손실 가능성이 높아진다
2. RNN의 고질적인 문제인 vanishing gradient 문제가 발생할 수 있다.
결국, seq2seq는 이 문제를 해결하기 위해 RNN 보정을 위한 Attention mechanism을 사용하게 된다.
Attention mechanism은 디코더에서 출력 단어를 생성하는 각 step에서 source sentence(input sentence)의 중요한 정보를 더 잘 활용할 수 있도록, 집중(Attention)할 수 있도록 돕는다.
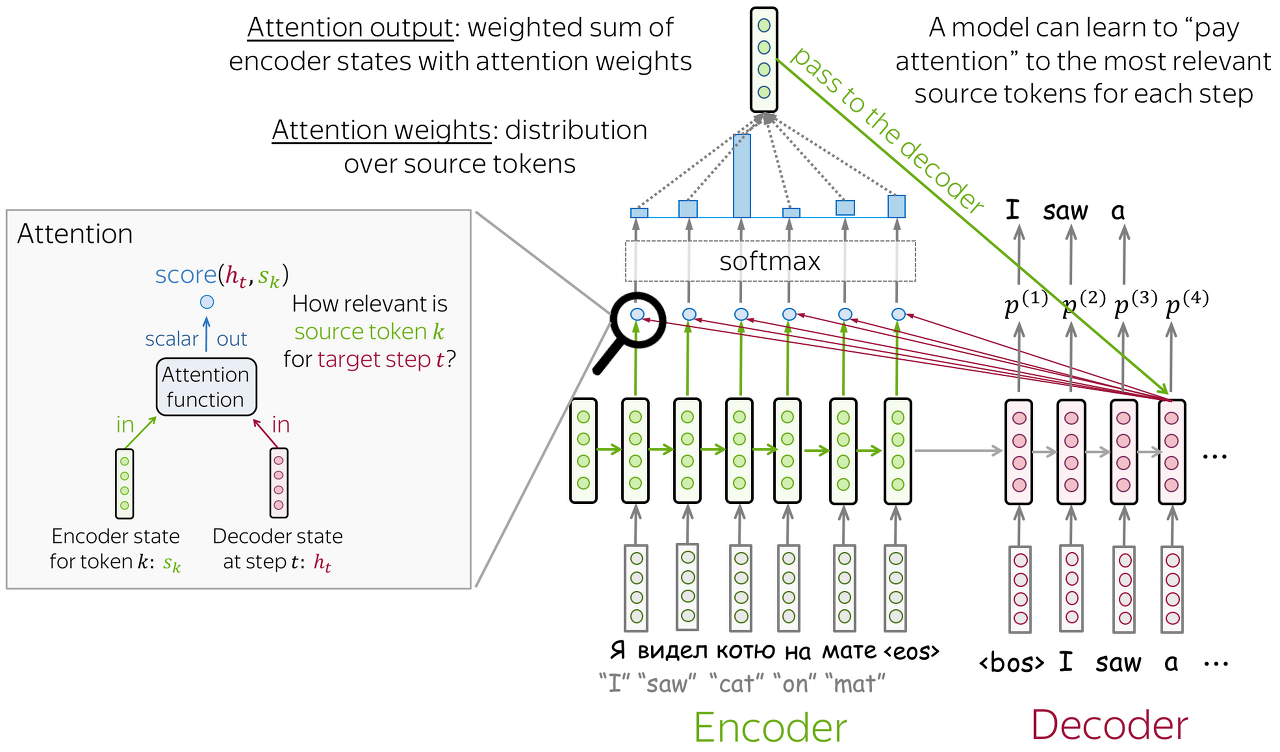
Attention Input
$h_{t}$ : 디코더 상태
$s_1, s_2, .. ., s_m$ : 인코더의 상태
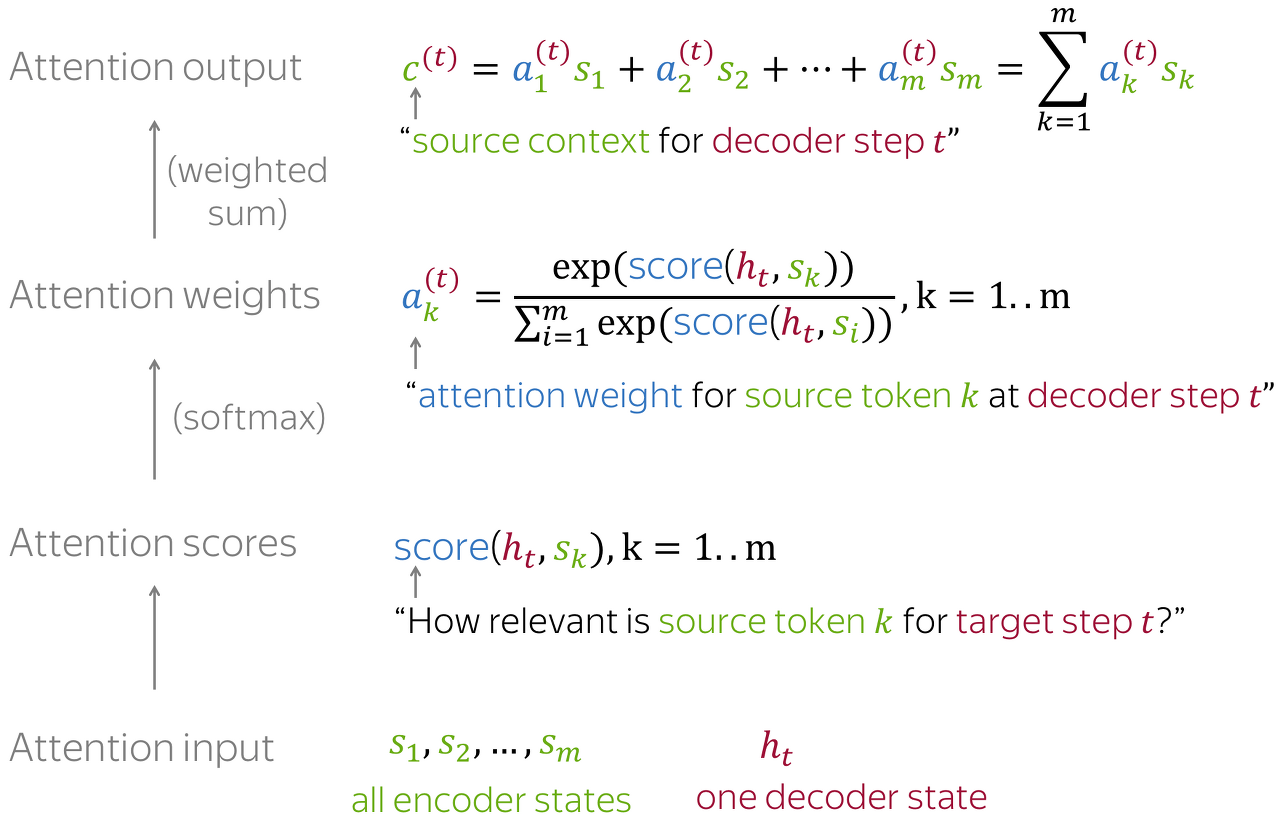
Attention Scores
$socre(h_{t},s_{k})$
$h_{t}$ : 디코더 상태 (디코더의 hidden state)
$s_{k}$ : 각 인코더의 상태 (인코더의 hidden state)
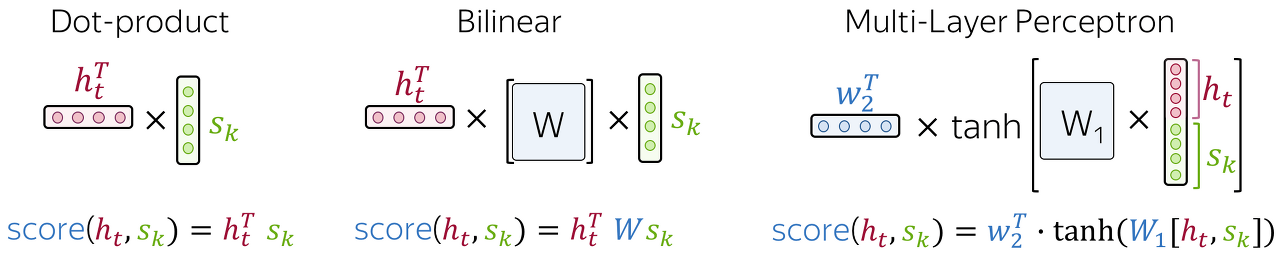
source sequence의 k번째 token이 output sequence의 t번째 step과 얼마나 관련이 있는지 평가하게 된다. 관련성이 높을수록 점수가 높아지므로, decoder는 해당 token에 더 집중하게 된다.
Multi-Layer Perceptron에 사용되는 tanh 함수의 경우 하나의 hidden layer에서만 사용된다.
Attention Weights
$a_{k}^{t} = \frac{exp(socre(h_{t},s_{k}))}{\sum_{i=1}{exp(socre(h_{t},s_{i}))}}$
Softmax 함수를 사용하여 Attention Distribution를 구한다
Attention Output
$c^{t}=\sum_{k=1} a_{k}^{t}s_{k}$
각 인코더의 은닉 상태(hidden state)와 attention weights을 곱하고, 최종적으로 더하는 과정을 거친다.
즉 weighted sum을 진행한다.
Self-Attention
Self-attention(혹은 intra-attention)는 단일 시퀀스의 다른 위치들을 연관시켜 시퀀스의 표현을 계산하는 방법이다
(단어 사이의 관련성을 구하는 방법)
Self-attention은 입력 시퀀스의 각 위치에 대한 표현을 계산할 때, 다른 위치들의 정보를 참조하여 그 위치의 중요성을 결정하게 된다. (이를 context sensitive한 encoding이라고 말한다)
이는 text의 자동 이해를 개선하는데 도움이 될 수 있다.
Languague modeling이나 sentiment analysis와 같은 작업에 유용하게 사용된다.
Query = Key = Value (→ value가 같다는 것이 아니라 vector의 reference가 같다는 말)
Evaluation of NLP
BLEU Score(Bilingual Evaluation Understudy Score)
n-gram에 기반하여 2개의 sentences (기계 번역 결과(hypothesis)/사람이 직접 번역한 결과(reference))사이의 유사성을 평가하는 방법 (기본적으로 완전히 같아야 같다고 취급한다)
일반적으로 unigram, bigram, trigram, 4-gram score의 평균을 계산한다.
2-gram BLEU
hypothesis : "The cat is on the mat"
reference : "There is a cat on the mat”
- hypothesis에서 2-gram을 추출한다 ,: “The cat”, “cat is”, “is on”, “on the”, “the mat”
- 각 2-gram이 reference에 얼마나 많이 나타나는지 계산한다 : "The cat"은 0번, "cat is"는 0번, "is on"은 1번, "on the"은 1번, "the mat"은 1번
- (2.)의 빈도수를 hypothesis의 2-gram의 빈도수와 비교하여 최솟값을 취한다 : min(0, 1) = 0, min(0, 1) = 0, min(1, 1) = 1, min(1, 1) = 1, min(1, 1) = 1
- 이전 단계에서 얻은 최솟값들의 합을 hypothesis의 전체 2-gram 개수로 나누어 정확도를 계산한다: (0 + 0 + 1 + 1 + 1) / 5
BP(Brevity Penalty)를 계산한다- BP = $exp(1 - \frac{reference_length}{hypothesis_length}) = exp(1 - \frac{6}{5})$
- 최종적으로, BLEU 점수는 BP * precision으로 계산된다: BLEU = BP * precision
Perplexity
input text의 분포와 학습된 word의 분포와 같다면 같다고 취급한다
test set의 역확률(inverse probability)로, 단어 수로 정규화되며, 언어 모델링에서 자주 사용된다.
METEOR
BLEU와 유사하나, 동의어나 단어의 어근을 비교하는 추가 단계가 있다. (어근이 같다면 같은 언어라고 취급한다)
'🤖 ai logbook' 카테고리의 다른 글
| [NLP/자연어처리/Python] text generation 실습 (transformer 언어 번역) (0) | 2023.07.09 |
|---|---|
| [NLP/자연어처리/Python] text classification 실습 (0) | 2023.07.08 |
| [NLP/자연어처리] BERT & GPT & ChatGPT (0) | 2023.07.05 |
| [NLP/자연어처리] 트랜스포머(Transformer) (0) | 2023.07.04 |
| [NLP/자연어처리] 자연어 처리에서의 순환 신경망 (RNN in Natural Language Processing) (0) | 2023.07.01 |
| [cs231n/Spring 2023] Lecture 4: Neural Networks and Backpropagation (0) | 2023.07.01 |
| [NLP/자연어처리] 정보 검색 & 단어 임베딩(Information Retrieval & Word Embedding) (0) | 2023.07.01 |
| [NLP/자연어처리] 감정 분석 & 문장에 대한 확률 (Sentiment Classification & Probabilities to Sentences) (0) | 2023.06.29 |