reference
Language Modeling
주어진 단어들로부터 아직 모르는 단어를 예측하는 작업
그리고 언어 모델은 단어 시퀀스에 확률을 할당(assign) 하는 일을 하는 모델
ex1) Machine Translation:
P(high winds tonite) > P(large winds tonite)
ex2) Spell Correction
The office is about fifteen minuets from my house
P(about fifteen minutes from) > P(about fifteen minuets from)
ex3) Speech Recognition
P(I saw a van) >> P(eyes awe of an)
Probabilistic Language Models
P(An adorable little boy is spreading smiles)의 확률을 어떻게 구할 것인가?
-> 확률의 연쇄법칙 (Chain Rule)에 의존해보자
Chain Rule
4개의 확률이 조건부 확률의 관계를 가지는 경우 (조건부 확률의 연쇄법칙)
$$P(A,B,C,D) = P(A)P(B|A)P(C|A,B)P(D|A,B,C)$$
4개가 아닌 n개에 대한 일반화
$$P(x_1, x_2, x_3 ... x_n) = P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)...P(x_n|x_1 ... x_{n-1})$$
joint probability of words in sentence (문장에 대한 확률)
다시, 처음으로 돌아가서 P(An adorable little boy is spreading smiles)의 확률을 구하면?
$$P(w_1, w_2, w_3, w_4, w_5, ... w_n) = \prod_{i=1}P(w_{i} | w_{1}, ... , w_{i-1})$$$$P(\text{An}) × P(\text{adorable|An}) × P(\text{little|An adorable}) × P(\text{boy|An adorable little}) × P(\text{is|An adorable little boy})$$
이미지로 이해하면 다음과 같다

그러면, 이 때 이전 단어로부터 다음 단어에 대한 확률은 어떻게 구할 것인가?
다음과 같이 나눠서 세는 방법이 맞을까?
$$P\text{(is|An adorable little boy}) = \frac{\text{count(An adorable little boy is})}{\text{count(An adorable little boy })}$$
이 때 가능한 문장이 너무 많으며, 방대한 양의 데이터가 필요하다.
N-gram Model
참고 : Google Ngram Viewer (https://books.google.com/ngrams/)
n-gram 모델에서는 Markov 가정을 기반으로 이전 n-1개의 단어가 주어졌을 때 다음 단어의 확률이 그 이전의 단어들과는 독립적이라고 가정한다.
N-gram Model
"An adorable little boy is spreading smiles"
unigrams : an, adorable, little, boy, is, spreading, smiles
bigrams : an adorable, adorable little, little boy, boy is, is spreading, spreading smiles
trigrams : an adorable little, adorable little boy, little boy is, boy is spreading, is spreading smiles
4-grams : an adorable little boy, adorable little boy is, little boy is spreading, boy is spreading smiles
Markov Assumption
현재 상태가 이전 상태에만 의존한다
$$P(w_1, w_2, w_3, w_4, w_5, ... w_n) = \prod_{i}P(w_{i} | w_{i-k}, ... , w_{i-1})$$
가장 간단한 Unigram Model
n = 1
$$P(w_1, w_2, w_3, w_4, w_5, ... w_n) = \prod_{i}P(w_{i})$$
Bigram Model
n = 12
$$P(w_1, w_2, w_3, w_4, w_5, ... w_n) = \prod_{i}P(w_{i}|w_{i-1})$$
probabilities Estimation (Bigram)
최대우도법(Maximum Likelihood Estimate)으로 Bigram 확률을 추정할 수 있다.
$$P(w_{i}|w_{i-1}) = \frac{count(w_{i_1}, w_{i})}{count(w_{i_1})}$$
$$P\text{(happy|am}) = \frac{\text{count(am,happy})}{\text{count(am})}$$
N-gram Language Model의 한계
Avoid underflow
작은 확률값이 곱해지면서 0에 가까워지는 현상
이를 방지하기 위해 log 확률을 사용한다.
log 확률을 사용하면 확률의 곱셈이 덧셈으로 바뀌어 underflow를 방지할 수 있다.
Overfitting
test corpus와 training corpus가 유사하다면 N-gram은 잘 작동한다.
하지만 현실에서는 그렇지 않은 경우가 많으므로, 일반화 성능이 좋은 모델을 훈련해야 한다.
(training set에는 없지만, test set에 등장하는 단어들을 고려한다)
Laplace smoothing (aka add-one smoothing)
이러한 한계를 해결하기 위한 가장 간단한 방법은 모든 n-gram을 한 번 이상 본 척하는 것이다.
모든 카운트에 1($\delta$ : Add-$\delta$)을 추가하면 된다
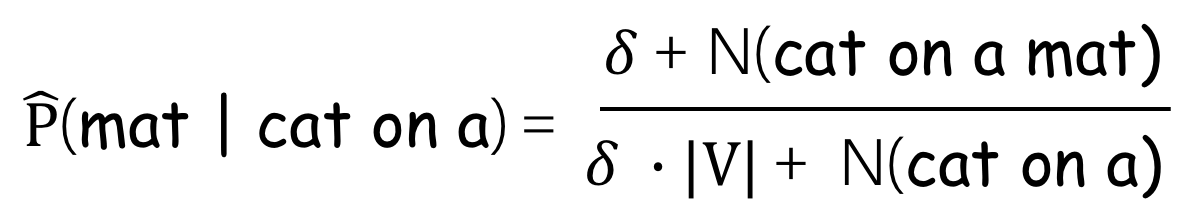
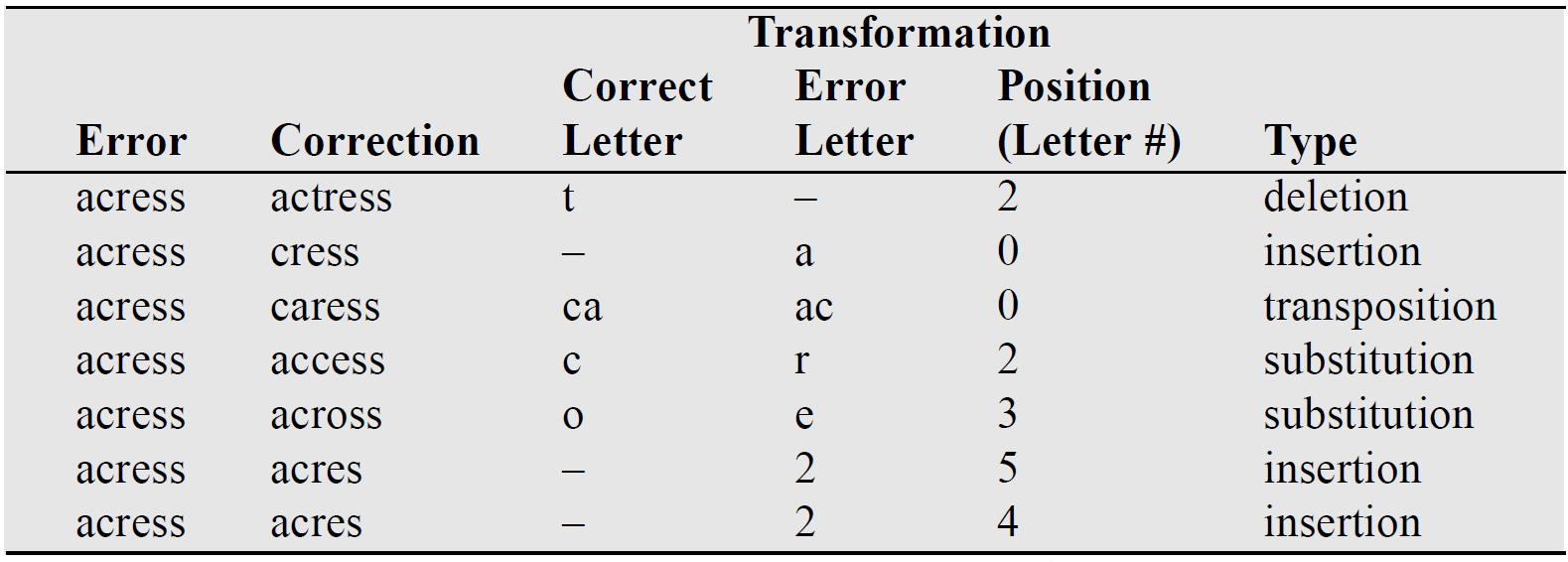
Spelling Tasks
참고 : https://norvig.com/spell-correct.html
Spelling Errors의 Type
non-word error
"graffe" 대신 "giraffe"
real-word error
우연히 실제 영어 단어가 되는 철자 오류(실제 단어 오류)를 포함하게 된 경우. "there" 대신 "three"
동음이의어나 유사음이의어의 잘못된 철자를 대체한 경우. "dessert" 대신 "desert", "piece" 대신 "peace"
이런 Spelling Error를 교정하는데 가장 널리 사용되는 알고리즘이 Noisy Channel Model이다.
The Noisy Channel Model for Spelling
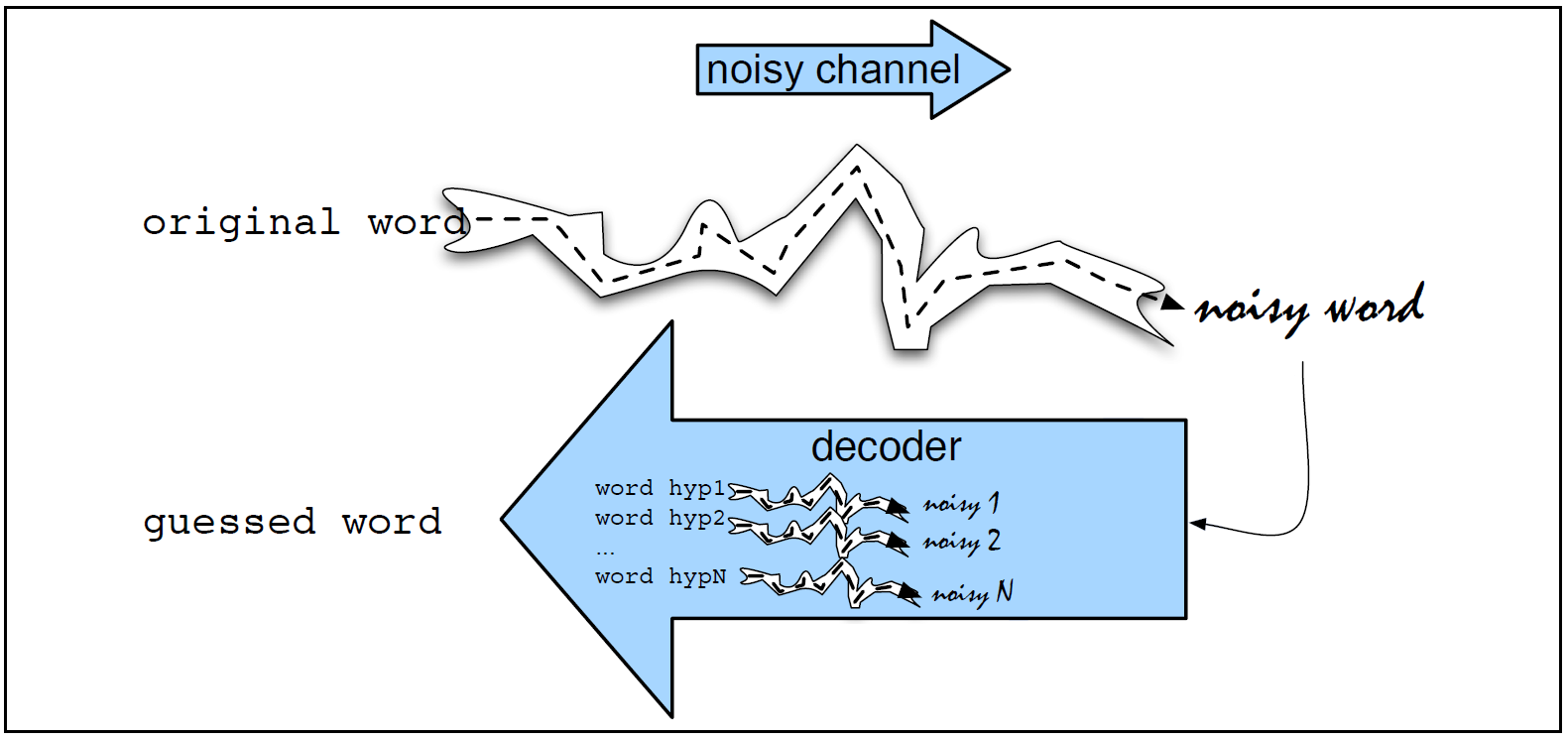
1. 입력 단어 (예를 들어 Graffe)로 부터 가능한 모든 후보들을 생성한다.
2. 후보들에 대해 정확한 단어로의 복원 가능성을 평가하여 가장 적절한 후보(guessed word, 예를 들어 Griaffe)를 선택한다.
그리고, 이 과정은 Bayesian Rule을 따른다.
$$\hat{w} = \underset{ w∈V }{ \text{ argmax } }\frac{ P(O|w)P(w) }{ P(O) } = \underset{ w∈V }{ \text{ argmax } } P(O|w)P(w)$$
이에 따라, error 사이에 삽입, 삭제, 대체, 전치와 같은 단순한 변형만 존재한다고 가정하고
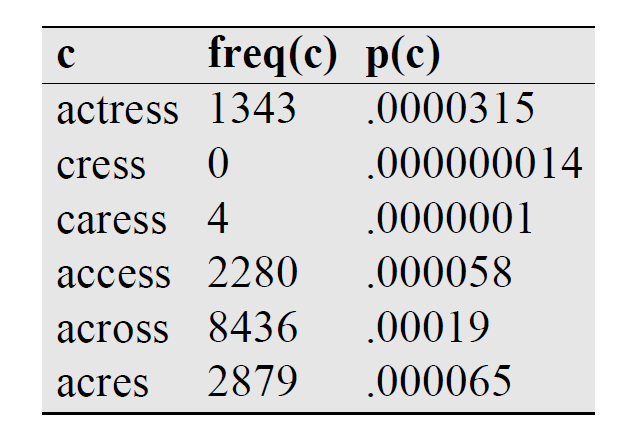
"acress"라는 word에 해당 가정과 Bayesian Rule을 적용하여 candidate correction table을 생성하면 다음과 같다.