
reference
NLP(Natural Language Processing) 작업을 위해 텍스트 데이터를 수집해야 한다.
이 때의 텍스트 데이터를 Corpus라 한다.
이렇게 수집된 Corpus를 사용하기 위하여 데이터를 Tokenization하는 과정이 필요하며,
여기서 '토큰(token)'은 텍스트에서 의미를 갖는 최소 단위로 분할된 단어, 문장 부호, 숫자 등을 의미한다.
여기서 '토큰화'를 수행하는 도구가 '토크나이저(tokenizer)'이다.
1. 말뭉치 ( corpus )
텍스트 데이터의 집합
ex) Google Corpora
https://www.english-corpora.org/googlebooks/

2. Word Tokenization
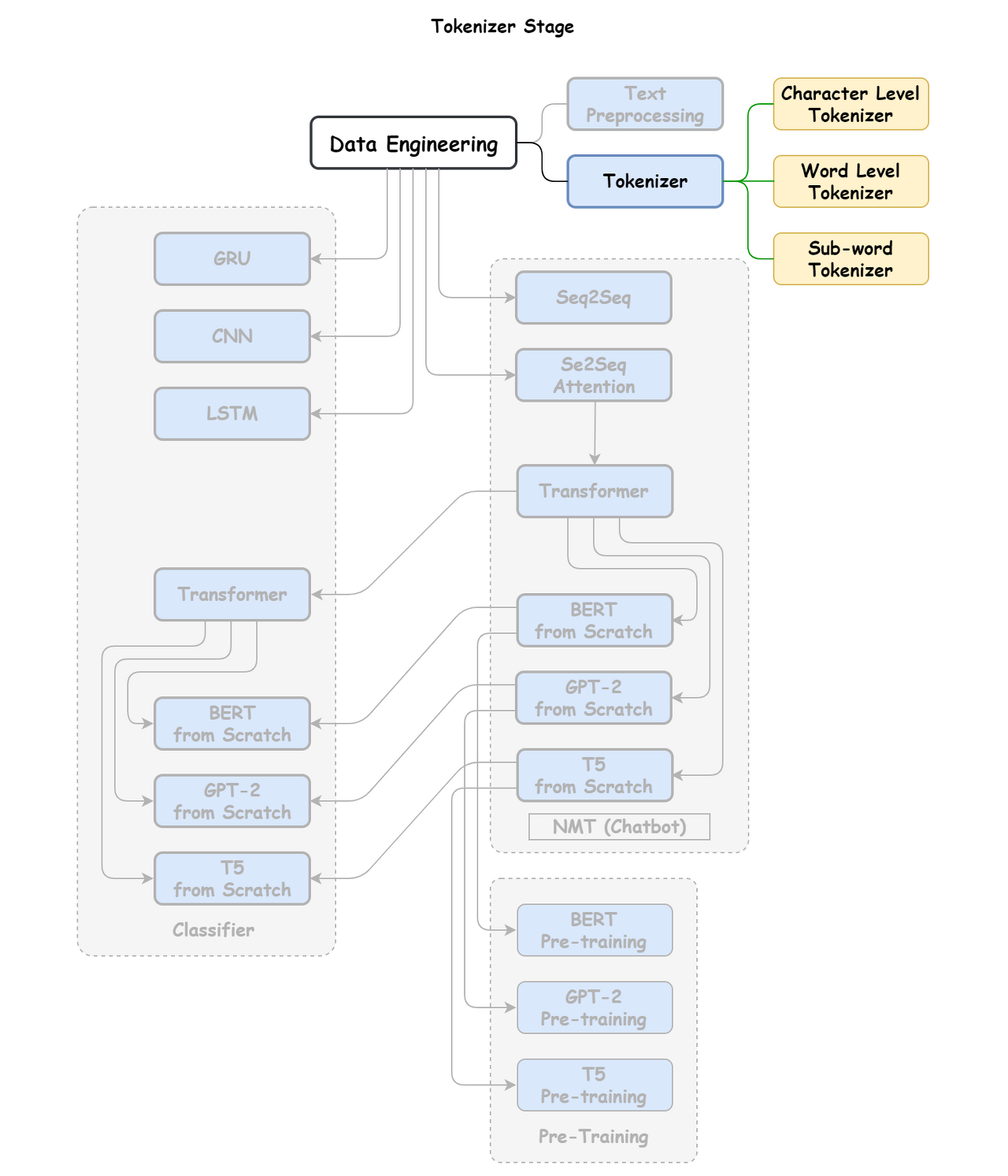
Tokenization
더 작은 단위로 분할하는 프로세스
“Let us learn tokenization.”
Word -> [“Let”, “us”, “learn”, “tokenization.”]
Subword -> [“Let”, “us”, “learn”, “token”, “ization.”]
Character -> [“L”, “e”, “t”, “u”, “s”, “l”, “e”, “a”, “r”, “n”, “t”, “o”, “k”, “e”, “n”, “i”, “z”, “a”, “t”, “i”, “o”, “n”, “.”]
Word Normalization
표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만듬
Case folding (대, 소문자 통합)
대소문자를 구분하지 않고 모두 소문자로 바꾸는 것. 이 과정을 거치면 대소문자를 구분하지 않고 문자열을 비교할 수 있다.
Lemmatization (표제어 추출)
단어의 원형을 찾는 과정
이 과정을 거치면 단어의 형태가 변하지 않고 원형을 찾아낼 수 있다.
예를 들어, “am”, “is”, "are"와 같은 동사를 원형인 "be"로 바꿀 수 있다.
➡ Morphological Parsing
Stems와 Affixes를 분석하는 과정
이 과정을 거치면 단어의 형태소를 찾아낼 수 있다.
Lemmatization은 이러한 형태소 분석을 통해 단어의 원형을 찾는 과정이다.
Stems (어간) : 단어의 핵심 부분
Affixes (접사) : 단어의 접두사나 접미사
Stemming (어간 추출)
단어의 어근을 찾아내는 과정
이 과정을 거치면 단어의 어근을 추출할 수 있다.
예를 들어, “running”, “runs”, "ran"은 모두 "run"이라는 어근을 가지고 있다.
Lemmatization vs Stemming
Lemmatization
am → be
the going → the going
having → haveStemming
am → am
the going → the go
having → hav
Subword tokenization
단어를 의미 단위로 나누는 것이 아니라, 의미 단위보다 작은 단위(subword)로 나누는 것
알고리즘
- Byte Pair Encoding (BPE)
- WordPiece
- SentencePiece, Unigram
Byte-Pair Encoding (BPE)
논문 : https://arxiv.org/pdf/1508.07909.pdf
transformer-based models에 널리 사용되는 토큰화 방법
가장 많이 등장하는 문자열 쌍을 하나의 문자로 대체하는 과정을 반복하여 subword를 만듬.
BPE 과정
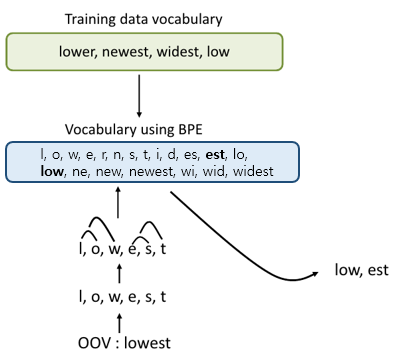
1. 말뭉치의 모든 단어에 단어 끝 기호를 추가한다. ( "__" )
2. 말뭉치의 단어를 문자로 토큰화한다.