
Standford University - CS231n(Convolutional Neural Networks for Visual Recognition)
Stanford University CS231n: Deep Learning for Computer Vision
✔ reference
YouTube
cs231n 2강 Image classification pipeline - YouTube
Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition - YouTube
Doc
https://yganalyst.github.io/dl/cs231n_1
https://yerimoh.github.io/DL206/
https://biology-statistics-programming.tistory.com/53
https://velog.io/@cha-suyeon/CS231n-Lecture-9-%EA%B0%95%EC%9D%98-%EC%9A%94%EC%95%BD
https://velog.io/@fbdp1202/CS231n-%EC%A0%95%EB%A6%AC-9.-CNN-Architectures-rp6rx3zy
https://yerimoh.github.io/DL206/
https://velog.io/@cha-suyeon/CS231n-4%EA%B0%95-%EC%A0%95%EB%A6%AC-Introduction-to-Neural-Networks
Image Classification
no obvious way to hard-code the algorithm for recognizing a cat, or other classes.
-> 고양이와 나머지를 분류할 hard coding 할 수 있는 명백한 알고리즘이 존재하지 않는다.
Difficults : Viewpoint의 변화, Scale 변화, 변형, 조명 상태, 가려짐, 배경과 유사한 경우 등
- Viewpoint variation(시점 변화). 객체의 단일 인스턴스는 카메라에 의해 시점이 달라질 수 있다.
- Scale variation(크기 변화). 비주얼 클래스는 대부분 그것들의 크기의 변화를 나타낸다(이미지의 크기뿐만 아니라 실제 세계에서의 크기까지 포함함).
- Deformation(변형). 많은 객체들은 고정된 형태가 없고, 극단적인 형태로 변형될 수 있다.
- Occlusion(가려짐). 객체들은 전체가 보이지 않을 수 있다. 때로는 물체의 매우 적은 부분(매우 적은 픽셀)만이 보인다.
- Illumination conditions(조명 상태). 조명의 영향으로 픽셀 값이 변형된다.
- Background clutter(배경과 유사) 객체가 주변 환경에 섞여(blend) 알아보기 힘들게 된다.
- Intra-class variation(내부클래스의 다양성). 분류해야할 클래스는 범위가 큰 것들이 많다. 예를 들어 의자 의 경우, 매우 다양한 형태의 객체가 있다.
Machine Learning: 데이터 기반 방법 Data-Driven Approch
- Collect a dataset of images and labels
- Use Machine Learning algorithms to train a classifier
- Evaluate the classifier on new images
Nearest Neighbor
- 가장 가까운 이웃 찾기
- 초기 접근은 Nearest Neighbor classifer로, 실제로는 거의 사용되지 않지만 접근 방식에 대한 아이디어를 얻을 수 있다.
- 이는 내가 갖고 있는 이미지들과 가장 가까운(유사한) 이미지라고 판단하면 어떨까? 라는 idea에서 시작되었다.
- 필요한 작업 : Train, Predict

모든 data(images), labels을 기억

test_images와 유사한 training image를 찾고, 해당 label를 예측
Q. how does the classification speed depend on the size of the training data?
A. linearly.
Q. with N examples, how fast are training and prediction?
A. Train O(1), predict O(N)
→ 좋지 않다. 우리가 원하는 것은 prediction을 빠르게(fast)하는 것. training은 느려도(slow) 괜찮다.
⇒ test time performance is usually much more important.
CNN : expensive training. but, cheep test evaluation
K-nearest neighbor
K-Nearest Neighbors : Summary
- In image classification we start with a training set of images and labels, and must predict labels on the test set
- The K-Nearest Neighbors classifier predicts labels based on the K nearest training examples
- Distance metric and K are hyperparameters
- Choose hyperparameters using the validation set
- Only run on the test set once at the very end!
Parameter of K-Nearest Neighbors : K, Distance Metric
- take majority vote from K closest points 가까운 이웃 K개 찾고(distance metric) 투표
Distance Metric
L1 distance (Manhattan)
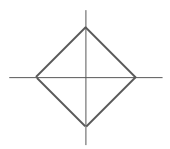
- 어떤 좌표계를 사용하냐에 따라 값이 바뀌며, 좌표축의 영향을 받기 때문에 boundary 부자연스러움
- 각 성분이 개별적인 의미를 가지고 있을 때 사용
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)L2 distance (Euclidean)
$d_2(I_1,I_2) = \sqrt{\sum{(I_1^p-I_2^p})^2}$
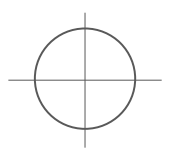
- 원점을 기준으로 모든 거리가 같음. 경계가 조금 더 부드러움
- 요소들간의 실질적인 의미가 없는 경우 사용
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))
These are hyperparameters: choices about the algorithms themselves.
→ best value of k, best distance 를 결정하는 것
Setting Hyperparameters
학습 전에 반드시 선택해야 함.
Idea #1 : training data 중 적합한 hyperparameters 선택하는 경우

→ 문제 : K = 1 은 training data에서 항상 완벽하게 동작한다. 하지만, 새로운 데이터에서는 그러지 않는다.→ 과적합 발생
Idea #2 : test data 중 적합한 hyperparameters 선택하는 경우

→ 문제 : 새로운 데이터에 대해서 어떻게 알고리즘이 진행될지 예측할 수 없으며, test data는 성능 평가를 위해 끝까지 남겨야 하는 최후의 보루이다.
✔ Idea #3 : train, validation로 분할한다. val 중에서 hyperparameters를 선택하고, test에서 평가한다. (val은 train 중 약 20%)

Cross-Validation
만약 Train data 개수가 적다면?
Idea #4 : Cross-Validation을 사용한다. fold로 data를 나눠, fold 중 하나로 validation을 진행하고, 나머지는 train 데이터로 사용하는 방법. validation으로 사용할 fold를 바꿔가며 결과를 average한다.
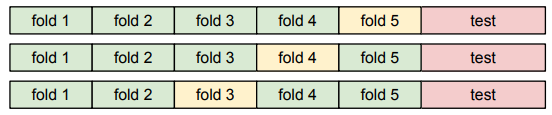
→ small datasets는 유용하게 사용하지만, deep learning에서는 사용하지 않는다. (많은 학습시간이 걸림)
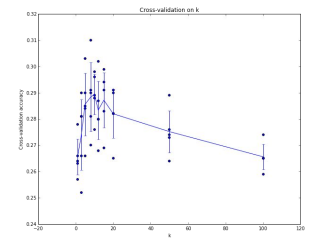
해당 그래프는 k에 대한 5-fold cross-validation 그래프이다.
k 마다 5개의 outcome point가 존재하며,
bar는 표준편차(standard deviation)을 나타내고,
선은 mean을 통과한다.
해당 그래프에서 약 k가 7일 때 평균이 가장 높은 것을 확인할 수 있으며, 평균이 가장 높은 것이 best k 값이다.
Image와 Distance의 관계
Pixel distance에 대한 K-Nearest Neighbor는 현실에서는 절대로 사용해서는 안된다.
→ test time이 오래걸리고, 사진간의 distance가 유의미하지 않기 때문
- terrible performance at test time
- distance metrics on pixels are not infomative
→ 아래 3개의 image는 동일한 image가 아니지만, 동일한 L2 distance 값을 갖게 된다.

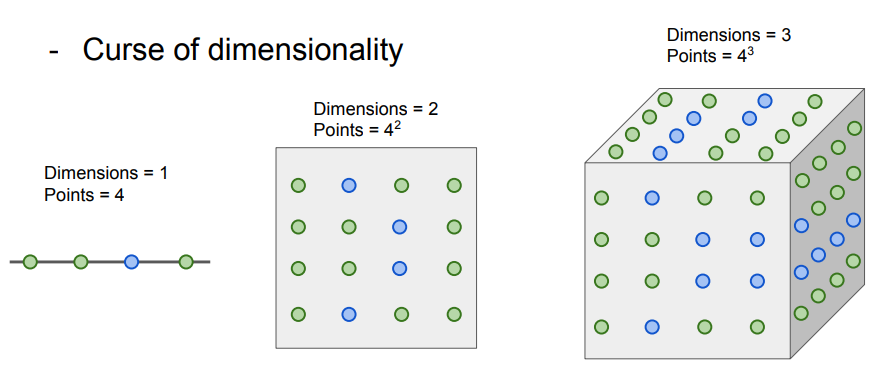
차원의 저주 (curse of dimensionality)
K-Nearest Neighbors이 잘 동작하려면 많은 데이터가 필요하다
→ 학습 데이터는 차원이 증가할 때마다 기하급수적으로 증가한다.
Linear Classifiers
- 입력 데이터의 선형 조합으로 출력값을 계산하는 분류 모델.
- Neural Network와 CNN의 기반이 되는 알고리즘
- Linear Classifier → Parametric Approach
(training data의 정보(입력 데이터의 특징)를 요약하여 parameter weight에 저장 → test time 적게 걸림)- Nearest Neighbors → Non-Parametic Approach
- Train 시간 O(N), Test 시간 O(1)
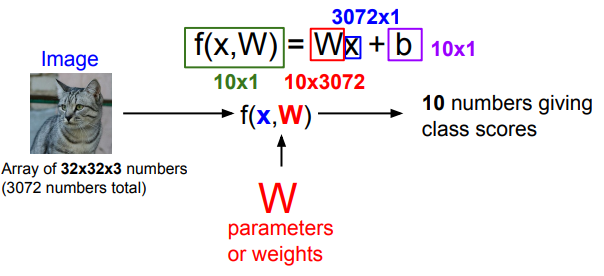
Parametric Model의 두가지 성분 : W, b
Image(x) = 3072x1 array즉 여기서 control 할 수 있는 대상은 W뿐이고, W의 차원을 우리가 맞춰줘야 한다.
Interpreting a Linear Classifier : Algebraic / Visual / Geometric viewpoints
Algebraic Viewpoint (대수적 관점)
Example. 4 pixels, 3 classes
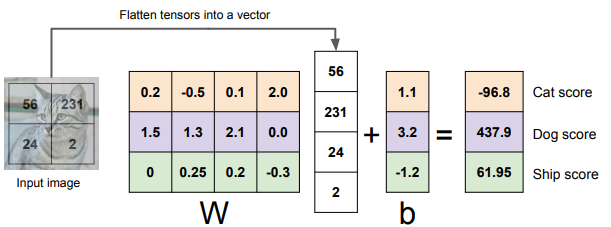
Wx+b = f(x,W)
(3x4)*(4x1) + (3x1) = (3x1)
Visual Viewpoint (시각적 관점)
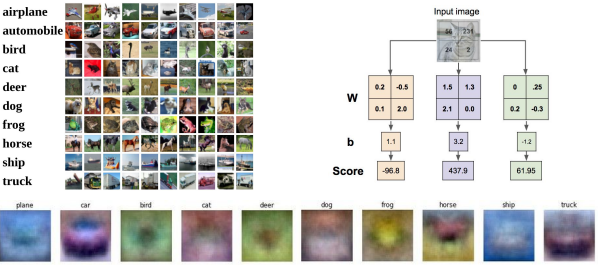
Q. What does the linear classifier do?
A. Counting colors at different special position.
Geometric Viewpoint (기하적 관점)
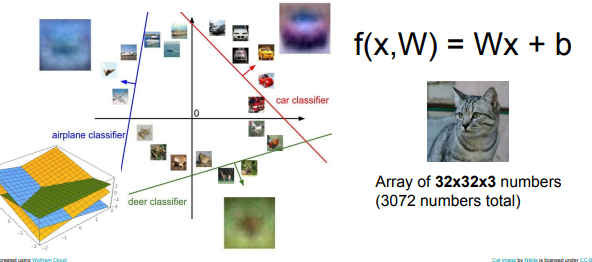
Hard cases for a linear classifier
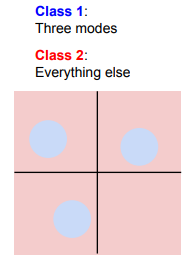
Linear Classification으로 분류할 수 없는 경우
1. XOR
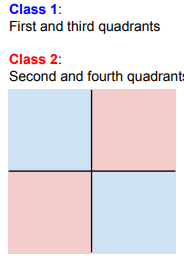
2. 도넛

3. Multimodal
Loss Function : SVM Softmax loss
Choose a good W
- Define a loss function that quantifies our unhappiness with the scores across the training data.
- Come up with a way of efficiently finding the parameters that minimize the loss function. (optimization)

- $x_i$ is image
- $y_i$ is (integer) label
- $f(x,W) = Wx$
dataset에 대한 loss는 loss들의 평균으로 나타낼 수 있음.
$$L = {1\over{N}}\sum{L_i(f(x_i,W), y_i)}$$
→ 얼마나 틀리게 분류했는가
Multiclass SVM loss
margin을 최대화하는 결정 경계를 찾는 것이 목적
scores vector : #s = f(x_i,W)#
SVM loss : - ${S_y}_i$ is correct score
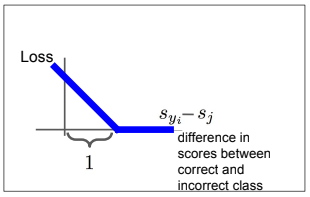

def L_i_vectorized(x, y, W) : // x: image, y : label, W : weight
scores : W.dot(x)
margins = np.maximum(0, scores - scores[y] + 1) // scores[y] : correct score
margins[y] = 0 // y와 동일한 위치에 대해서는 계산하지 않으므로 0
loss_i = np.sum(margins)
return loss_iQ1: What happens to loss if car scores decrease by 0.5 for this training example?
A1: 이미 car score는 다른 socre에 비해 높으며, correct class(car score)의 score가 margin 이상의 범위를 유지한다면, 값이 아무리 크게 변하더라도 loss 값은 변화하지 않는다.
Q2: what is the min/max possible SVM loss Li?
A2: (0 ~ ∞)
Q3: At initialization W is small so all s ≈ 0. What is the loss Li, assuming N examples and C classes?
A3: (C-1)x(margin-0)
L = Class 개수 - 1
→ sanity check (디버깅 전략)
Q4: What if the sum was over all classes? (including j = y_i)
A4: 최종 loss 값이 1 (safety margin) 증가한다.
정답 class만 빼고 정리하는 이유는 일반적으로 loss가 0이 되어야만 하기 때문
Q5: What if we used mean instead of sum?
A5: L=L/(C-1) 라고 해도 loss를 minimize한다는 목적 관점에서는 큰 의미는 없다.
class 수는 정해져 있어서 평균을 취해도 loss function을 rescale할 뿐 상관없음
정답 class가 정답이 아닌 class보다 더 높은 점수를 내기만을 바라고 있음
Q6: What if we used
A6: 제곱을 한다는 것은 비선형적으로 바꾼다(non-linear)는 의미로, 상황이 달라지며, 차이가 생긴다. (음숫값사라짐)
Q7: Suppose that we found a W such that L = 0. Is this W unique?
A7: W는 unique하지 않다. 여러개의 W가 생길 수 있으며, regularization으로 선택한다. loss 값이 0일때 임의의 상수를 곱해도 loss는 0이다.
Softmax Classifier
정답 값의 분포 비중을 보고 loss 값 결정
scores vector : $s = f(x_i;W)$
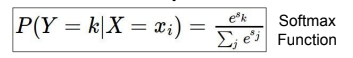

- score에 exponental을 취함
- 이 값에 대한 확률 분포 값 구함 (정규화를 통한)
- -log를 취함
score vector는 변함이 없지만, 이 score를 각 class에 대하여 unnormalized log-probabilities로 해석하여,
hinge loss(SVM)를 cross-entropy loss(Softmax)로 변환
$$L_i = -logP(Y=y_i|X=x_i) = -log({e^{sy_i} \over {\sum{e^{sj}}}})$$
→ cat에 대한 loss는 -log(0.13)
→ L은 얼마나 틀렸는지를 나타내는 것이므로 - 부호를 붙임
→ 정확한 class의 log의 확률을 최대화(-log 확률을 최소화)
Q1: What is the min/max possible softmax loss Li?
A1: (0 ~ ∞)
Q2: Usually at initialization W is small so all s ≈ 0. What is the loss? At initialization all sj will be approximately equal; what is the softmax loss Li, assuming C classes?
A2: -log$1\over{C}$ = logC. (If C = 10, then Li = log(10) ≈ 2.3)
→ sanity check
SVM vs Softmax


Q: What is cross-entropy loss? What is SVM loss?
A: cross-entropy loss > 0, SVM loss = 0
Q: What is the softmax loss and the SVM loss?
A: SVM은 loss 값이 불변하다 (둔감), softmax는 모든 인자들을 고려하므로 변화한다 (민감)
Q: What is the softmax loss and the SVM loss if I double the correct class score from 10 -> 20?
A: Cross-entropy loss will decrease, SVM loss still 0
'🤖 ai logbook' 카테고리의 다른 글
| [NLP/자연어처리] 자연어 처리에서의 순환 신경망 (RNN in Natural Language Processing) (0) | 2023.07.01 |
|---|---|
| [cs231n/Spring 2023] Lecture 4: Neural Networks and Backpropagation (0) | 2023.07.01 |
| [NLP/자연어처리] 정보 검색 & 단어 임베딩(Information Retrieval & Word Embedding) (0) | 2023.07.01 |
| [NLP/자연어처리] 감정 분석 & 문장에 대한 확률 (Sentiment Classification & Probabilities to Sentences) (0) | 2023.06.29 |
| [NLP/자연어처리] 언어 모델에서의 나이브베이즈 (Naive Bayes as a Language Model) (1) | 2023.06.28 |
| [NLP/자연어처리] 언어 모델링(Language Modeling) (0) | 2023.06.28 |
| [NLP/자연어처리] 단어 토큰화(Word Tokenization) (0) | 2023.06.27 |
| [cs231n/Spring 2023] Lecture 3: Regularization and Optimization (0) | 2023.06.26 |