
Reference
- <파이썬 한권으로 끝내기>, 데싸라면▪빨간색 물고기▪자투리코드, 시대고시기획 시대교육
변수 Y에 원인이 되는 변수가 여러 개(n) 포함되는 형태로 표현
$$Y=B_0+\sum_{i=1}^{n}{B_i}{x_i}$$
Y = 예측값
n = 독립변수의 수
i번째 특성변수를 $x_i$라 함
$B_i$은 i번째 모델 파라미터
방법
1. scikit-learn의 Ridge
$$RidgedMSE(B)=MSE(B)+a\frac{1}{2}\sum_{i=1}^{n}{B_i}^2$$
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html
2. scikit-learn의 Lasso
$$LassoMSE(B)=MSE(B)+a\sum_{i=1}^{n}{|B_i|}$$
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html
3. scikit-learn의 Elastic Net
$$ElasticNetMSE(B)=MSE(B)+ra\sum_{i=1}^{n}{|B_i|}+\frac{1-r}{2}{a}\sum_{i=1}^{n}{B_i}^2$$
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.ElasticNet.html
1. scikit-learn의 Ridge
class sklearn.linear_model.Ridge(alpha=1.0, *, fit_intercept=True, copy_X=True, max_iter=None, tol=0.0001, solver='auto', positive=False, random_state=None)
- alpha (float 또는 ndarray, default=1.0): 규제 항의 강도를 조절하는 매개변수입니다. 값이 클수록 규제가 강해지고, 모델의 복잡성이 감소합니다.
- fit_intercept (bool, default=True): 상수항(intercept)을 학습할지 여부를 결정하는 매개변수입니다. True로 설정하면 상수항이 모델에 포함됩니다.
- copy_X (bool, default=True): 입력 데이터를 복사하여 사용할지 여부를 결정하는 매개변수입니다. True로 설정하면 입력 데이터를 복사하여 사용하고, False로 설정하면 입력 데이터를 직접 사용합니다.
- max_iter (int, default=None): 최대 반복 횟수를 지정하는 매개변수입니다. solver 매개변수에 따라 사용될 수 있습니다.
- tol (float, default=0.0001): 최적화 알고리즘의 수렴 조건을 지정하는 매개변수입니다.
- solver (str 또는 callable, default='auto'): 최적화에 사용할 알고리즘을 지정하는 매개변수입니다. 'auto', 'svd', 'cholesky', 'sparse_cg', 'sag' 등의 값을 사용할 수 있습니다.
- positive (bool, default=False): 계수(coefficient)의 값이 양수로 제한되도록 설정하는 매개변수입니다. True로 설정하면 계수의 값이 양수로 제한됩니다.
- random_state (int, RandomState instance, default=None): 난수 생성을 위한 시드(seed) 값입니다.
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
x = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
y = diabetes.target
from sklearn.linear_model import Ridge
import numpy as np
alpha = np.logspace(-3, 1, 5) # 0.001, 0.010, 0.100, 1.000, 10.000 생성
data = []
for i, a in enumerate(alpha) :
ridge = Ridge(alpha = a)
ridge.fit(x, y)
data.append(pd.Series(np.hstack([ridge.coef_])))
# pd.Series는 1차원 배열과 유사한 자료구조로, 인덱스와 값으로 구성
# ridge.coef_ : [ -8.99617741 -238.89632766 520.26740319 323.42359592 -720.24482811 421.39975285 66.73350259 164.44802215 725.33555818 67.47681002]
# np.hstack([lasso.coef_] : [ -8.99617741 -238.89632766 520.26740319 323.42359592 -720.24482811 421.39975285 66.73350259 164.44802215 725.33555818 67.47681002]
# pd.Series(np.hstack([lasso.coef_])) :
# 0 -8.996177
# 1 -238.896328
# 2 520.267403
# 3 323.423596
# 4 -720.244828
# 5 421.399753
# 6 66.733503
# 7 164.448022
# 8 725.335558
# 9 67.476810
df_ridge = pd.DataFrame(data, index=alpha)
df_ridge.columns = x.columns
df_ridgeimport matplotlib.pyplot as plt
plt.semilogx(df_ridge)
plt.xticks(alpha, labels=np.log10(alpha))
plt.legend(labels=df_ridge.columns, bbox_to_anchor=(1,1))
plt.title("Ridge")
plt.xlabel('alpha')
plt.ylabel('Coefficient (size)')
plt.axhline(y=0, linestyle='--', color='black', linewidth=3)
from sklearn.linear_model import LinearRegression
lr=LinearRegression()
lr.fit(x,y)
plt.axhline(y=0, linestyle='--', color='black', linewidth=2)
plt.plot(df_ridge.loc[0.001], '^-', label='Ridge alpha = 0.001')
plt.plot(df_ridge.loc[0.010], 's', label='Ridge alpha = 0.010')
plt.plot(df_ridge.loc[0.100], 'v', label='Ridge alpha = 0.100')
plt.plot(df_ridge.loc[1.000], '*', label='Ridge alpha = 1.000')
plt.plot(df_ridge.loc[10.000], 'o-', label='Ridge alpha = 10.000')
plt.plot(lr.coef_, label="LinearRegression")
plt.xlabel('Feature Names')
plt.ylabel('Coefficient (size)')
plt.legend(bbox_to_anchor=(1,1))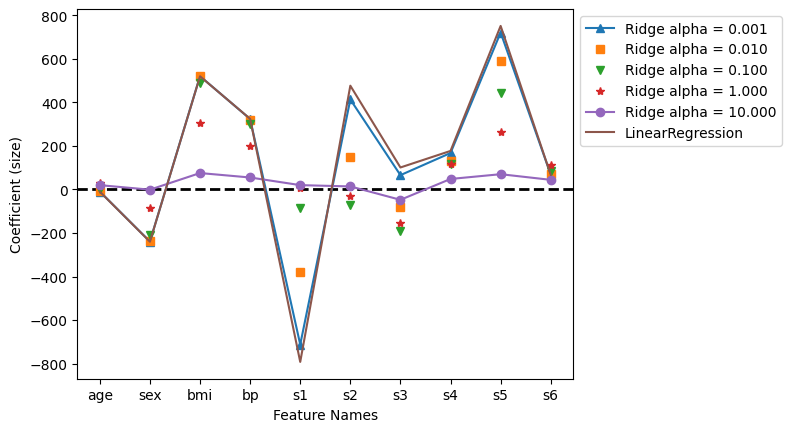
2. scikit-learn의 Lasso
class sklearn.linear_model.Lasso(alpha=1.0, *, fit_intercept=True, precompute=False, copy_X=True, max_iter=1000, tol=0.0001, warm_start=False, positive=False, random_state=None, selection='cyclic')
- alpha (float, default=1.0): 규제 항의 강도를 조절하는 매개변수입니다. 값이 클수록 규제가 강해지고, 모델의 복잡성이 감소합니다.
- fit_intercept (bool, default=True): 상수항(intercept)을 학습할지 여부를 결정하는 매개변수입니다. True로 설정하면 상수항이 모델에 포함됩니다.
- precompute (bool or array-like, default=False): 사전 계산된 Gram 행렬(Gram matrix)을 사용할지 여부를 결정하는 매개변수입니다. True로 설정하면 사전 계산된 Gram 행렬을 사용합니다. False로 설정하면 알고리즘이 필요에 따라 자체적으로 계산합니다.
- copy_X (bool, default=True): 입력 데이터를 복사하여 사용할지 여부를 결정하는 매개변수입니다. True로 설정하면 입력 데이터를 복사하여 사용하고, False로 설정하면 입력 데이터를 직접 사용합니다.
- max_iter (int, default=1000): 최대 반복 횟수를 지정하는 매개변수입니다.
- tol (float, default=0.0001): 최적화 알고리즘의 수렴 조건을 지정하는 매개변수입니다.
- warm_start (bool, default=False): 이전 호출의 솔루션을 재사용하여 학습을 계속할지 여부를 결정하는 매개변수입니다.
- positive (bool, default=False): 계수(coefficient)의 값이 양수로 제한되도록 설정하는 매개변수입니다. True로 설정하면 계수의 값이 양수로 제한됩니다.
- random_state (int, RandomState instance, default=None): 난수 생성을 위한 시드(seed) 값입니다.
- selection (str, default='cyclic'): 변수 선택을 위한 알고리즘을 지정하는 매개변수입니다. 'cyclic', 'random' 등의 값을 사용할 수 있습니다.
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
x = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
y = diabetes.target
from sklearn.linear_model import Lasso
import numpy as np
alpha = np.logspace(-3, 1, 5)
data = []
for i, a in enumerate(alpha) :
lasso = Lasso(alpha = a)
lasso.fit(x, y)
data.append(pd.Series(np.hstack([lasso.coef_])))
df_lasso = pd.DataFrame(data, index=alpha)
df_lasso.columns = x.columns
df_lassoimport matplotlib.pyplot as plt
plt.semilogx(df_lasso)
plt.xticks(alpha, labels=np.log10(alpha))
plt.legend(labels=df_lasso.columns, bbox_to_anchor=(1,1))
plt.title("Lasso")
plt.xlabel('alpha')
plt.ylabel('Coefficient (size)')
plt.axhline(y=0, linestyle='--', color='black', linewidth=3)
from sklearn.linear_model import LinearRegression
lr=LinearRegression()
lr.fit(x,y)
plt.axhline(y=0, linestyle='--', color='black', linewidth=2)
plt.plot(df_lasso.loc[0.001], '^-', label='Lasso alpha = 0.001')
plt.plot(df_lasso.loc[0.010], 's', label='Lasso alpha = 0.010')
plt.plot(df_lasso.loc[0.100], 'v', label='Lasso alpha = 0.100')
plt.plot(df_lasso.loc[1.000], '*', label='Lasso alpha = 1.000')
plt.plot(df_lasso.loc[10.000], 'o-', label='Lasso alpha = 10.000')
plt.plot(lr.coef_, label="LinearRegression")
plt.xlabel('Feature Names')
plt.ylabel('Coefficient (size)')
plt.legend(bbox_to_anchor=(1,1))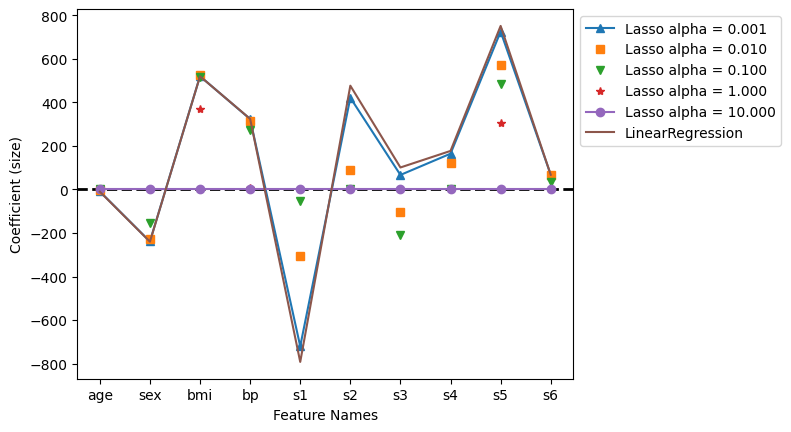
3. scikit-learn의 ElasticNet
class sklearn.linear_model.ElasticNet(alpha=1.0, *, l1_ratio=0.5, fit_intercept=True, precompute=False, max_iter=1000, copy_X=True, tol=0.0001, warm_start=False, positive=False, random_state=None, selection='cyclic')
- alpha (float, default=1.0): 규제 항의 강도를 조절하는 매개변수입니다. 값이 클수록 규제가 강해지고, 모델의 복잡성이 감소합니다.
- l1_ratio (float, default=0.5): L1 규제와 L2 규제의 비율을 조절하는 매개변수입니다. 0에 가까울수록 L2 규제가 강해지고, 1에 가까울수록 L1 규제가 강해집니다.
- fit_intercept (bool, default=True): 상수항(intercept)을 학습할지 여부를 결정하는 매개변수입니다. True로 설정하면 상수항이 모델에 포함됩니다.
- precompute (bool or array-like, default=False): 사전 계산된 Gram 행렬(Gram matrix)을 사용할지 여부를 결정하는 매개변수입니다. True로 설정하면 사전 계산된 Gram 행렬을 사용합니다. False로 설정하면 알고리즘이 필요에 따라 자체적으로 계산합니다.
- max_iter (int, default=1000): 최대 반복 횟수를 지정하는 매개변수입니다.
- copy_X (bool, default=True): 입력 데이터를 복사하여 사용할지 여부를 결정하는 매개변수입니다. True로 설정하면 입력 데이터를 복사하여 사용하고, False로 설정하면 입력 데이터를 직접 사용합니다.
- tol (float, default=0.0001): 최적화 알고리즘의 수렴 조건을 지정하는 매개변수입니다.
- warm_start (bool, default=False): 이전 호출의 솔루션을 재사용하여 학습을 계속할지 여부를 결정하는 매개변수입니다.
- positive (bool, default=False): 계수(coefficient)의 값이 양수로 제한되도록 설정하는 매개변수입니다. True로 설정하면 계수의 값이 양수로 제한됩니다.
- random_state (int, RandomState instance, default=None): 난수 생성을 위한 시드(seed) 값입니다.
- selection (str, default='cyclic'): 변수 선택을 위한 알고리즘을 지정하는 매개변수입니다. 'cyclic', 'random' 등의 값을 사용할 수 있습니다.
from sklearn.datasets import load_diabetes
import pandas as pd
diabetes = load_diabetes()
x = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
y = diabetes.target
from sklearn.linear_model import ElasticNet
import numpy as np
alpha = np.logspace(-3, 1, 5)
data = []
for i, a in enumerate(alpha) :
ela = ElasticNet(alpha = a)
ela.fit(x, y)
data.append(pd.Series(np.hstack([ela.coef_])))
df_ela = pd.DataFrame(data, index=alpha)
df_ela.columns = x.columns
df_elaimport matplotlib.pyplot as plt
plt.semilogx(df_ela)
plt.xticks(alpha, labels=np.log10(alpha))
plt.legend(labels=df_ela.columns, bbox_to_anchor=(1,1))
plt.title("Elastic")
plt.xlabel('alpha')
plt.ylabel('Coefficient (size)')
plt.axhline(y=0, linestyle='--', color='black', linewidth=3)
from sklearn.linear_model import LinearRegression
lr=LinearRegression()
lr.fit(x,y)
plt.axhline(y=0, linestyle='--', color='black', linewidth=2)
plt.plot(df_ela.loc[0.001], '^-', label='Elastic alpha = 0.001')
plt.plot(df_ela.loc[0.010], 's', label='Elastic alpha = 0.010')
plt.plot(df_ela.loc[0.100], 'v', label='Elastic alpha = 0.100')
plt.plot(df_ela.loc[1.000], '*', label='Elastic alpha = 1.000')
plt.plot(df_ela.loc[10.000], 'o-', label='Elastic alpha = 10.000')
plt.plot(lr.coef_, label="LinearRegression")
plt.xlabel('Feature Names')
plt.ylabel('Coefficient (size)')
plt.legend(bbox_to_anchor=(1,1))
'🥇 certification logbook' 카테고리의 다른 글
| [python 데이터 핸들링] 판다스 연습 튜토리얼 - 02 Filtering & Sorting (0) | 2023.06.09 |
|---|---|
| [python 데이터 핸들링] 판다스 연습 튜토리얼 - 01 Getting & Knowing Data (0) | 2023.06.08 |
| [ADsP] 비지도학습 - 자기조직화지도(SOM) & 다차원척도법(MDS) (0) | 2023.06.08 |
| 앙상블 (Ensemble) - 랜덤 포레스트 분류 (Random Forest Classifier) (0) | 2023.06.07 |
| 다항 회귀 (Polynomial Regression Model) (0) | 2023.06.06 |
| 단순 선형 회귀 (Simple Linear Regression Model) (1) | 2023.06.06 |
| 분석환경 설정 (Visual Studio Code + 주피터노트북) (0) | 2023.06.05 |
| [ADsP] 비지도학습 - 주성분 분석(PCA) (1) | 2023.06.05 |