
Reference
- <파이썬 한권으로 끝내기>, 데싸라면▪빨간색 물고기▪자투리코드, 시대고시기획 시대교육
독립 변수가 하나인 경우 데이터의 특징을 가장 잘 설명하는 직선을 학습하는 것
의료비 지출액 = $b_0$+$b_1$*나이
DataSet
https://www.kaggle.com/datasets/mirichoi0218/insurance
Medical Cost Personal Datasets
Insurance Forecast by using Linear Regression
www.kaggle.com
방법
1. scikit-learn의 LinearRegression
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
2. scikit-learn의 SGDRegressor
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDRegressor.html
1. scikit-learn의 LinearRegression
class sklearn.linear_model.LinearRegression(*, fit_intercept=True, copy_X=True, n_jobs=None, positive=False)
- fit_intercept: 상수항(intercept)을 모델에 포함할지 여부를 지정하는 매개변수입니다. 기본값은 True로, 상수항을 모델에 포함합니다.
- copy_X: 입력 데이터를 복사할지 여부를 지정하는 매개변수입니다. 기본값은 True로, 입력 데이터를 복사합니다. 이는 입력 데이터를 수정하지 않고 원본 데이터를 보존할 수 있도록 합니다.
- n_jobs: 모델의 학습을 병렬화하기 위한 작업 수를 지정하는 매개변수입니다. 기본값은 None으로, 단일 작업을 실행합니다. 만약 정수 값을 지정하면 해당 수만큼의 작업을 병렬로 실행합니다.
- positive: 모델의 예측값을 양수로 제한할지 여부를 지정하는 매개변수입니다. 기본값은 False로, 제약이 없습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
data = pd.read_csv('./insurance.csv')
x=data['age']
y=data['charges']
x=np.array(data['age'])
y=np.array(data['charges'])
x=x.reshape(1338,1)
y=y.reshape(1338,1)
lr=LinearRegression()
lr.fit(x,y)
- fit(X, y[, sample_weight])
Fit linear model.
모델을 학습
- X : 학습 데이터. 2차원 array
- y : 타깃데이터
- sample_weight : 가중치
print("선형 회귀 모델 결과")
print("절편", lr.intercept_, "계수", lr.coef_)
print(lr.score(x,y))
# 선형 회귀 모델 결과
# 절편 [3165.88500606] 계수 [[257.72261867]]
# 0.08940589967885804
- score(X, y[, sample_weight])
Return the coefficient of determination of the prediction.
- X : 테스트 샘플 array로 입력
- y : X의 실제 값
- sample_weight : 가중치
결정계수를 float로 반환.
- coef_
array of shape (n_features, ) or (n_targets, n_features)Estimated coefficients for the linear regression problem. If multiple targets are passed during the fit (y 2D), this is a 2D array of shape (n_targets, n_features), while if only one target is passed, this is a 1D array of length n_features.
선형 회귀 문제에 대한 추정된 계수
- intercept_
float or array of shape (n_targets,)Independent term in the linear model. Set to 0.0 if fit_intercept = False.
선형 모델의 독립항(절편)
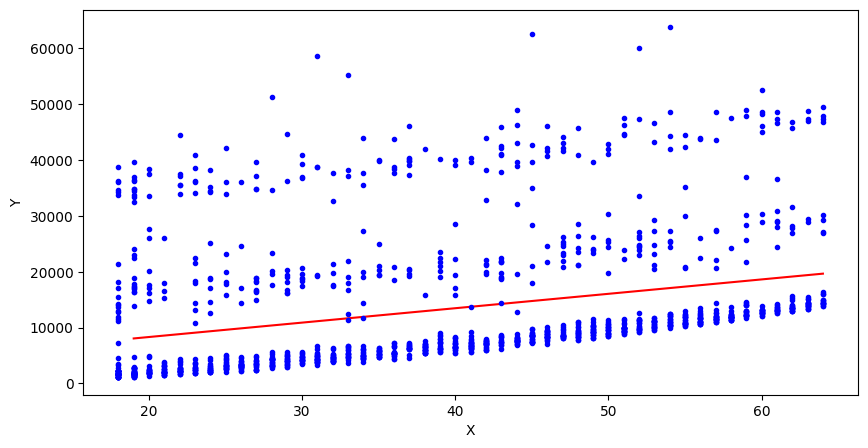
x_new=[[19],[64]] # 새로운 데이터 샘플
y_hat=lr.predict(x_new) # 예측 값
print(y_hat)
#[[ 8062.61476073]
# [19660.13260074]]
- predict(X)
Predict using the linear model.
- X : 데이터 샘플
예측값을 array로 반환
plt.figure(figsize=(10,5))
plt.plot(x_new, y_hat, "-r")
plt.plot(x,y,"b.")
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
2. scikit-learn의 SGDRegressor
class sklearn.linear_model.SGDRegressor(loss='squared_error', *, penalty='l2', alpha=0.0001, l1_ratio=0.15, fit_intercept=True, max_iter=1000, tol=0.001, shuffle=True, verbose=0, epsilon=0.1, random_state=None, learning_rate='invscaling', eta0=0.01, power_t=0.25, early_stopping=False, validation_fraction=0.1, n_iter_no_change=5, warm_start=False, average=False)
- loss: 손실 함수를 지정하는 매개변수입니다. 기본값은 'squared_error'로 최소제곱 오차를 나타냅니다.
- penalty: 정규화(regularization) 항을 지정하는 매개변수입니다. 기본값은 'l2'로 L2 정규화를 사용합니다.
- alpha: 정규화 항의 강도를 조절하는 매개변수입니다. 기본값은 0.0001입니다.
- l1_ratio: Elastic Net 모델에서 L1 정규화 항의 비율을 조절하는 매개변수입니다. 기본값은 0.15입니다.
- fit_intercept: 상수항(intercept)을 모델에 포함할지 여부를 지정하는 매개변수입니다. 기본값은 True입니다.
- max_iter: 최대 반복 횟수를 지정하는 매개변수입니다. 기본값은 1000입니다.
- tol: 반복 알고리즘의 수렴 조건을 지정하는 매개변수입니다. 기본값은 0.001입니다.
- shuffle: 반복할 때마다 데이터를 섞을지 여부를 지정하는 매개변수입니다. 기본값은 True입니다.
- verbose: 학습 과정에서 출력 메시지를 제어하는 매개변수입니다. 기본값은 0으로 출력하지 않음을 의미합니다.
- epsilon: Huber 손실 함수에서 임계값을 지정하는 매개변수입니다. 기본값은 0.1입니다.
- random_state: 난수 생성기의 시드를 지정하는 매개변수입니다. 기본값은 None으로, 실행할 때마다 다른 결과를 얻습니다.
- learning_rate: 학습률 스케줄링 방법을 지정하는 매개변수입니다. 기본값은 'invscaling'으로 역 스케일링 학습률을 사용합니다.
- eta0: 초기 학습률을 지정하는 매개변수입니다. 기본값은 0.01입니다.
- power_t: 역 스케일링 학습률에 사용되는 지수를 지정하는 매개변수입니다. 기본값은 0.25입니다.
- early_stopping: 조기 종료를 사용할지 여부를 지정하는 매개변수입니다. 기본값은 False입니다.
- validation_fraction: 조기 종료에 사용되는 검증 데이터의 비율을 지정하는 매개변수입니다. 기본값은 0.1입니다.
- n_iter_no_change: 조기 종료를 위한 반복 횟수를 지정하는 매개변수입니다. 기본값은 5입니다.
- warm_start: 이전 학습 결과를 재사용할지 여부를 지정하는 매개변수입니다. 기본값은 False입니다.
- average: 평균 SGD를 사용할지 여부를 지정하는 매개변수입니다. 기본값은 False입니다.
import numpy as np
import pandas as pd
from sklearn.linear_model import SGDRegressor
data = pd.read_csv('./insurance.csv')
x = np.array(data['age'])
y = np.array(data['charges'])
x=x.reshape(1338,1)
y=y.reshape(1338,1)
sgd_reg = SGDRegressor(max_iter=1000, random_state=34)
sgd_reg.fit(x,y.ravel())
- max_iter
int, default=1000
The maximum number of passes over the training data (aka epochs). It only impacts the behavior in the fit method, and not the partial_fit method.
훈련 데이터에 대한 최대 패스 수
- random_state
int, RandomState instance, default=None
Used for shuffling the data, when shuffle is set to True. Pass an int for reproducible output across multiple function calls. See Glossary.
shffle이 true로 설정된 경우 데이터 셔플에 사용.
random_state 값은 모델의 결과를 제어하는 데 사용되는 초기화 값
같은 random_state 값을 사용하면 항상 동일한 결과를 얻을 수 있음
print("SGD 회귀 모델 결과")
print("절편",sgd_reg.intercept_,"계수",sgd_reg.coef_)
# SGD 회귀 모델 결과
# 절편 [9057.21833765] 계수 [484.13243757]x_new=[[19],[64]]
y_hat=sgd_reg.predict(x_new)
print(y_hat)
# [18255.73465154 40041.69434233]plt.figure(figsize=(10,5))
plt.plot(x_new, y_hat, "-r")
plt.plot(x,y,"b.")
plt.xlabel('X')
plt.ylabel('Y')
plt.show()

'🥇 certification logbook' 카테고리의 다른 글
| [ADsP] 비지도학습 - 자기조직화지도(SOM) & 다차원척도법(MDS) (0) | 2023.06.08 |
|---|---|
| 앙상블 (Ensemble) - 랜덤 포레스트 분류 (Random Forest Classifier) (0) | 2023.06.07 |
| 다중 회귀 (Multiple Regression Model) (0) | 2023.06.07 |
| 다항 회귀 (Polynomial Regression Model) (0) | 2023.06.06 |
| 분석환경 설정 (Visual Studio Code + 주피터노트북) (0) | 2023.06.05 |
| [ADsP] 비지도학습 - 주성분 분석(PCA) (1) | 2023.06.05 |
| [ADsP] 비지도학습 - 연관 분석 (0) | 2023.06.05 |
| [ADsP] 지도학습 - 분류 분석 (0) | 2023.06.05 |