
paper : https://arxiv.org/abs/2207.05833
github : https://github.com/amazon-science/earth-forecasting-transformer
Hong Kong University of Science and Technology & Amazon Web Services (AWS)
전통적으로 기상과 기후와 같은 지구 시스템의 예측은 복잡한 물리 기반 수치 시뮬레이션에 의존해 왔으며, 이러한 방식은 막대한 계산 자원을 필요로 하고, 동시에 높은 수준의 도메인 전문성을 요구한다.
하지만 최근에는 위성 관측을 포함한 다양한 센서 기술이 발전하면서, 방대한 양의 시공간 데이터가 축적되고 있고, 이를 바탕으로 한, 딥러닝을 활용한 데이터 기반 예측 모델이 여러 지구 시스템 예측 과제에서 높은 가능성을 보여주고 있다.
특히 Transformer와 같은 최신 딥러닝 아키텍처를 기상 및 기후 예측에 적용하려는 시도가 점점 늘고 있지만, 실제로 이 분야에서의 활용은 아직 제한적인 수준에 머물러 있는 상황이다.
해당 논문은 이러한 문제의식을 바탕으로, 기존 방법의 한계를 보완하고자 새로운 예측 모델을 제안했다.
Earthformer 모델
지구 시스템 예측을 위해 시공간 데이터를 처리하는 Trabsformer 기번 아키텍처
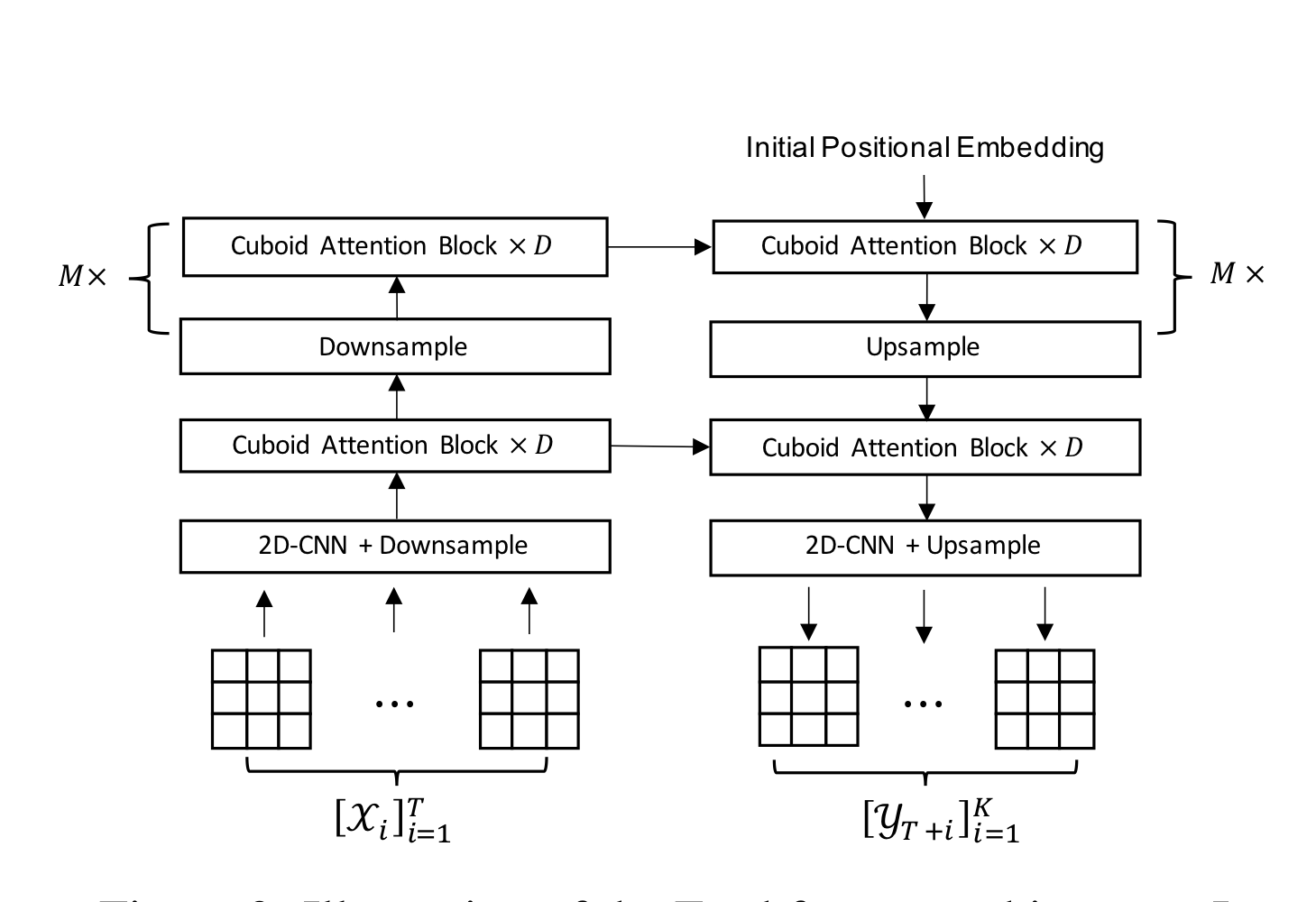
Earthformer는 기존의 CNN 및 RNN 기반 시계열 예측 모델이 가지는 한계를 보완하기 위해, 시공간 주의(attention) 메커니즘을 활용한 Transformer 아키텍처로 설계되었다.
이 모델의 핵심 구성 요소 중 하나는 큐보이드 어텐션(Cuboid Attention) 블록으로, 시공간 데이터를 여러 개의 큐보이드 단위로 나눈 뒤 각 조각에 대해 self-attention을 병렬로 적용함으로써 효율적인 학습을 가능하게 한다.
또한, 각 지역의 정보만으로는 전체 시스템의 동적 패턴을 완전히 이해하기 어렵기 때문에, Earthformer는 여러 개의 전역 벡터(global vectors)를 도입해 전체 상태를 요약하고 이를 각 큐보이드와 연결하는 방식을 채택했다.
실험 결과, 이 전역 벡터 기반 설계가 모델의 시공간 예측 성능 향상에 핵심적인 역할을 한다는 사실이 확인되었다.
Cuboid?
큐보이드(Cuboid)는 3차원 블록을 의미한다.
Earthformer 모델에서는 입력 데이터 χ(예: 시간에 따라 변화하는 위성 영상처럼 시공간 정보를 포함한 데이터)를 여러 개의 작은 3차원 블록으로 나눈다.
여기서 3차원은 시간(T), 공간(H×W), 채널(C)로 구성되며, 이 중 시공간 영역(T×H×W)을 기준으로 나누어 큐보이드를 만든다.
쉽게 말해, 하나의 큐보이드는 특정 시간 구간 동안의 특정 지역 영역을 나타내는 블록이라고 생각하면 된다.
이렇게 나뉜 각 큐보이드에 대해 self-attention을 적용하고, 병렬 처리함으로써 모델은 넓은 시공간 범위를 효율적으로 학습할 수 있다.
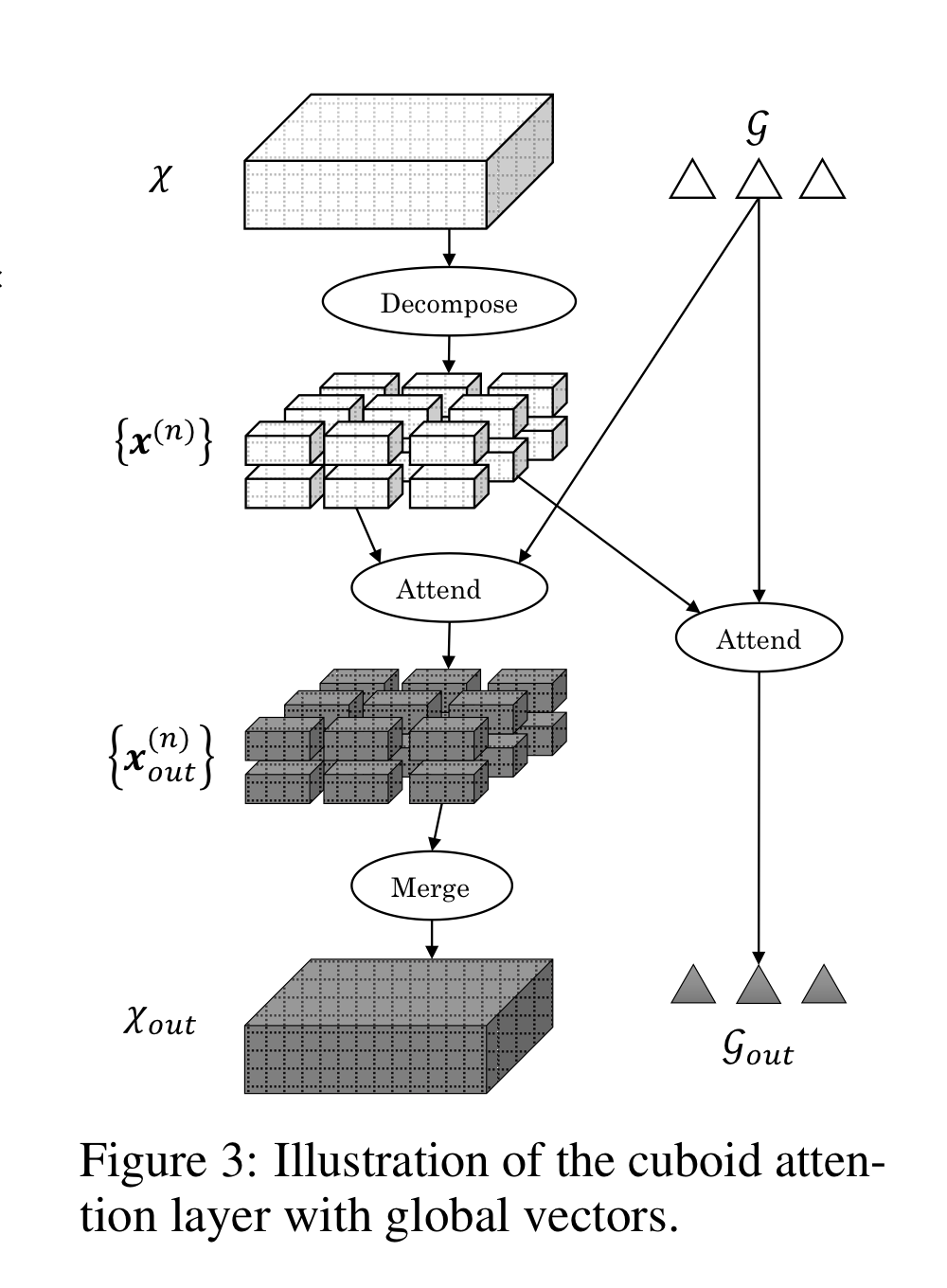
Cuboid Attention Block의 작동 방식
- Decompose
입력 텐서 χ를 여러 개의 큐보이드 {x⁽ⁿ⁾}로 분할한다.
각 큐보이드는 시공간 데이터의 일정 영역을 나타내는 3차원 블록으로, (T, H, W) 축을 따라 나뉜다. - Local or Dilated Attend
분할된 각 큐보이드 내부에서 self-attention을 수행하여, 시간적·공간적 관계를 학습한다.
이때 attention은 local 방식으로 인접 위치 간의 관계를 학습하거나,
dilated 전략을 통해 간격을 둔 위치들 간의 관계까지 고려할 수 있다.
사용되는 전략은 사전에 정의된 cuboid strategy 설정에 따라 달라진다. - Global Attend
큐보이드 간 정보 공유를 위해, 글로벌 벡터 G를 도입한다.
각 큐보이드는 이 전역 벡터와의 attention을 통해 개별 영역을 넘는 전역적 시공간 패턴을 학습한다. - Merge
attention 처리를 마친 큐보이드 {x⁽ⁿ⁾_out}들을 다시 병합하여 하나의 출력 텐서 χ_out을 구성한다.
이 결과는 시공간 관계가 반영된 통합 표현으로, 다음 층의 입력으로 활용된다.
모델 architecture
def forward(self, x, verbose=False):
"""
Parameters
----------
x : Tensor
입력 시퀀스 (B, T, H, W, C)
verbose : bool
중간 출력 shape을 출력할지 여부
Returns
-------
out : Tensor
예측 결과 시퀀스 (B, T_out, H, W, C_out)
"""
B, _, _, _, _ = x.shape
T_out = self.target_shape[0]
# 1. 초기 인코딩 (2D CNN + 다운샘플 등): 입력 시계열을 잠재 표현 공간으로 매핑
x = self.initial_encoder(x) # (B, T, H', W', D)
# 2. Cuboid Attention Block × D → Downsample → Cuboid Attention Block × D (M번 반복)
# 포지셔널 임베딩 추가 (시간+공간 위치 정보 포함)
x = self.enc_pos_embed(x)
# 인코더에 global vector 사용하는 경우, 초기 global vector 생성
if self.num_global_vectors > 0:
init_global_vectors = self.init_global_vectors.expand(
B, self.num_global_vectors, self.global_dim_ratio * self.base_units
)
# 인코더 실행: 입력 + global vector → 다층 memory 출력 + global vector 출력
mem_l, mem_global_vector_l = self.encoder(x, init_global_vectors)
else:
# 인코더 실행: 입력 → 다층 memory 출력
mem_l = self.encoder(x)
# verbose=True일 경우, 각 인코더 레이어 출력 shape 출력
if verbose:
for i, mem in enumerate(mem_l):
print(f"mem[{i}].shape = {mem.shape}")
# 3. Initial Positional Embedding. 디코더의 초기 입력(z0)을 생성 (인코더 마지막 출력 기반)
initial_z = self.get_initial_z(final_mem=mem_l[-1], T_out=T_out)
# 4. Cuboid Attention Block × D → Upsample → Cuboid Attention Block × D (M번 반복)
# 디코더 실행: 초기 z + 인코더 메모리 (+global vector)
if self.num_global_vectors > 0:
dec_out = self.decoder(initial_z, mem_l, mem_global_vector_l)
else:
dec_out = self.decoder(initial_z, mem_l)
# 5. 2D-CNN + Upsample
# 디코더 결과를 업샘플링/후처리
dec_out = self.final_decoder(dec_out) # (B, T_out, H, W, D)
# 최종 예측 projection (D → C_out)
out = self.dec_final_proj(dec_out) # (B, T_out, H, W, C_out)
return out
2D-CNN + Downsample
입력 영상에 대해 Conv2D를 적용해 피처 추출 및 다운샘플링
if initial_downsample_type == "conv":
self.initial_encoder = InitialEncoder(...)
elif initial_downsample_type == "stack_conv":
self.initial_encoder = InitialStackPatchMergingEncoder(...)
InitialEncoder
#self.conv_block = nn.Sequential([...]) # Conv2D → GroupNorm → Activation 반복
#self.patch_merge = PatchMerging3D(...) # 3D 패치 병합으로 다운샘플링 수행
def forward(self, x):
B, T, H, W, C = x.shape
if self.num_conv_layers > 0:
x = x.reshape(B * T, H, W, C).permute(0, 3, 1, 2) # → (B*T, C, H, W)
x = self.conv_block(x) # Conv2D Block
x = x.permute(0, 2, 3, 1) # → (B*T, H, W, C)
x = self.patch_merge(x.reshape(B, T, H, W, -1)) # → (B, T, H↓, W↓, C)
else:
x = self.patch_merge(x) # → (B, T, H↓, W↓, C)
return x # 최종 출력
InitialStackPatchMergingEncoder
for i in range(num_merge):
x = self.conv_block_list[i](x) # Conv
x = self.patch_merge_list[i](x) # Patch Merging ↓
Cuboid Attention Block × D → Downsample → Cuboid Attention Block × D (M번 반복)
인코더 역할. Cuboid Attention과 Downsample을 반복하며 multi-scale feature 생성
self.encoder = CuboidTransformerEncoder(
input_shape=(T_in, H_in, W_in, base_units),
base_units=base_units,
block_units=block_units,
scale_alpha=scale_alpha,
depth=enc_depth,
downsample=downsample,
downsample_type=downsample_type,
block_attn_patterns=enc_attn_patterns,
block_cuboid_size=enc_cuboid_size,
block_strategy=enc_cuboid_strategy,
block_shift_size=enc_shift_size,
num_heads=num_heads,
attn_drop=attn_drop,
proj_drop=proj_drop,
ffn_drop=ffn_drop,
gated_ffn=gated_ffn,
ffn_activation=ffn_activation,
norm_layer=norm_layer,
use_inter_ffn=enc_use_inter_ffn,
padding_type=padding_type,
use_global_vector=num_global_vectors > 0,
use_global_vector_ffn=use_global_vector_ffn,
use_global_self_attn=use_global_self_attn,
separate_global_qkv=separate_global_qkv,
global_dim_ratio=global_dim_ratio,
checkpoint_level=checkpoint_level,
use_relative_pos=use_relative_pos,
self_attn_use_final_proj=self_attn_use_final_proj,
# initialization
attn_linear_init_mode=attn_linear_init_mode,
ffn_linear_init_mode=ffn_linear_init_mode,
conv_init_mode=conv_init_mode,
down_linear_init_mode=down_up_linear_init_mode,
norm_init_mode=norm_init_mode,
)
- enc_depth = [D1, D2, D3]: 각 scale마다 cuboid attention block 반복 수
- 각 단계마다 Cuboid Attention Block 후, 필요시 downsample 수행
Initial Positional Embedding
디코더 입력 z에 위치 임베딩 부여
self.dec_pos_embed = PosEmbed(
embed_dim=mem_shapes[-1][-1], typ=pos_embed_type,
maxT=T_out, maxH=mem_shapes[-1][1], maxW=mem_shapes[-1][2])
- PosEmbed 클래스가 (T, H, W) 위치 정보를 학습된 임베딩으로 제공
- 이 embedding이 디코더 입력에 더해짐
Cuboid Attention Block × D → Upsample → Cuboid Attention Block × D (M번 반복)
디코더 역할. 인코더에서 추출된 메모리와 함께 cuboid cross/self attention을 사용해 시퀀스를 생성
self.decoder = CuboidTransformerDecoder(
target_temporal_length=T_out,
mem_shapes=mem_shapes,
cross_start=dec_cross_start,
depth=dec_depth,
upsample_type=upsample_type,
block_self_attn_patterns=dec_self_attn_patterns,
block_self_cuboid_size=dec_self_cuboid_size,
block_self_shift_size=dec_self_shift_size,
block_self_cuboid_strategy=dec_self_cuboid_strategy,
block_cross_attn_patterns=dec_cross_attn_patterns,
block_cross_cuboid_hw=dec_cross_cuboid_hw,
block_cross_shift_hw=dec_cross_shift_hw,
block_cross_cuboid_strategy=dec_cross_cuboid_strategy,
block_cross_n_temporal=dec_cross_n_temporal,
cross_last_n_frames=dec_cross_last_n_frames,
num_heads=num_heads,
attn_drop=attn_drop,
proj_drop=proj_drop,
ffn_drop=ffn_drop,
upsample_kernel_size=upsample_kernel_size,
ffn_activation=ffn_activation,
gated_ffn=gated_ffn,
norm_layer=norm_layer,
use_inter_ffn=dec_use_inter_ffn,
max_temporal_relative=T_in + T_out,
padding_type=padding_type,
hierarchical_pos_embed=dec_hierarchical_pos_embed,
pos_embed_type=pos_embed_type,
use_self_global=(num_global_vectors > 0) and use_dec_self_global,
self_update_global=dec_self_update_global,
use_cross_global=(num_global_vectors > 0) and use_dec_cross_global,
use_global_vector_ffn=use_global_vector_ffn,
use_global_self_attn=use_global_self_attn,
separate_global_qkv=separate_global_qkv,
global_dim_ratio=global_dim_ratio,
checkpoint_level=checkpoint_level,
use_relative_pos=use_relative_pos,
self_attn_use_final_proj=self_attn_use_final_proj,
use_first_self_attn=dec_use_first_self_attn,
# initialization
attn_linear_init_mode=attn_linear_init_mode,
ffn_linear_init_mode=ffn_linear_init_mode,
conv_init_mode=conv_init_mode,
up_linear_init_mode=down_up_linear_init_mode,
norm_init_mode=norm_init_mode,
)
- dec_depth = [D1', D2']: 각 scale에서 몇 번의 attention block을 사용할지 결정
- upsample_type="upsample"을 사용하면, Nearest interpolation 방식*으로 해상도 복원
* Nearest interpolation : 가장 가까운 픽셀 값을 그대로 복사해서 빈 공간을 채우는 가장 단순한 업샘플링 방법
2D-CNN + Upsample
업샘플링 이후 Conv2D를 적용해 피처 추출
if self.initial_downsample_type == "conv":
self.final_decoder = FinalDecoder(...)
elif self.initial_downsample_type == "stack_conv":
self.final_decoder = FinalStackUpsamplingDecoder(...)
FinalDecoder
# self.upsample = Upsample3DLayer(...) # 3D 업샘플링 (T는 그대로, H/W 복원)
# self.conv_block = nn.Sequential([...]) # Conv2D → GroupNorm → Activation 반복
def forward(self, x):
# x: (B, T, H↓, W↓, C)
x = self.upsample(x) # Upsample to (B, T, H, W, C)
if self.num_conv_layers > 0:
B, T, H, W, C = x.shape
x = x.reshape(B * T, H, W, C).permute(0, 3, 1, 2) # → (B*T, C, H, W)
x = self.conv_block(x) # Conv2D Block
x = x.permute(0, 2, 3, 1).reshape(B, T, H, W, -1) # → (B, T, H, W, C)
return x
FinalStackUpsamplingDecoder
for i in range(num_upsample):
x = self.upsample_list[i](x) # Upsample ↑
x = self.conv_block_list[i](x) # Conv
실험 데이터셋 및 방법론
연구진은 Earthformer의 효과와 구조적 우수성을 검증하기 위해, 먼저 MovingMNIST*와 Earthformer 논문에서 제안한 새로운 합성 시계열 데이터셋인 N-body MNIST* 데이터셋을 활용해 초기 실험을 진행했다.
이 과정을 통해 큐보이드 어텐션 블록의 유효성을 확인하고, 모델 구조에 적용할 수 있는 다양한 설계 선택지를 실험적으로 평가하여 최적 구성을 도출했다.
이후에는 실제 기상 데이터를 활용한 평가로 확장하여, 강우 레이더 영상을 기반으로 한 강우 예측(Precipitation Nowcasting) 과제와 엘니뇨(ENSO) 예측 과제에 Earthformer를 적용했다.
이러한 벤치마크 실험에서는 Earthformer의 성능을 U-Net, ConvLSTM, PredRNN 등 기존의 CNN 또는 RNN 기반 예측 모델들과 비교하여 평가하였다.
* MovingMNIST : 숫자(0~9)가 움직이는 방식으로 합성된 비디오 시퀀스 데이터셋, 각 시퀀스가 20 프레임으로 이루어진 총 10,000개의 영상 시퀀스로 구성됨

* N-body MNIST : 여러 개의 MNIST 숫자 이미지가 서로 중력 영향을 주고 받으며 움직이는 시뮬레이션 데이터셋
실험 결과

1. 기존 모델들: Rainformer, UNet, ConvLSTM 등은 흐릿하거나 숫자 형태가 무너진 결과를 보임. 특히 숫자가 합쳐지거나 왜곡되는 경향이 있음. MSE가 30~50 수준으로 높은 편.
2. Earthformer without global vectors: 지역 정보만 보고 예측했을 때는 숫자 형상은 어느 정도 보존되지만, 점점 퍼짐.
3. Earthformer (Full model): 가장 선명하고 정확한 숫자 형태 유지, MSE = 16.73, 가장 낮음
실험 결과, Earthformer는 강우 예측과 ENSO 예측에 사용된 실제 데이터셋 모두에서 기존의 최신 모델들을 능가하는 예측 성능을 보여주었다.
이는 Earthformer가 시공간 패턴을 보다 효과적으로 학습함으로써 전반적인 예측 정확도를 높였다는 점을 나타낸다.
특히, 전역 벡터를 포함한 Earthformer의 변형 모델은 전역 정보를 사용하지 않고 학습한 경우보다 일관되게 더 높은 성능을 기록했다.
여기에 더해, 계층적인 인코더-디코더 구조(coarse-to-fine 접근. 먼저 크게 파악하고, 그다음에 세부적인 정보를 다듬어가는 방식)를 적용함으로써 예측 정확도를 한층 더 향상할 수 있었다고 한다.
이러한 실험 결과는, 제안된 모델의 핵심 설계 요소들(전역 벡터와 계층적 구조)이 예측 성능 개선에 크게 기여함을 뚜렷하게 보여준다.
한계점 및 향후 연구 방향
Earthformer에는 몇 가지 한계가 존재한다.
1. 결정론적 예측의 한계
이 모델은 불확실성을 모형화하지 않는 결정론적(deterministic) 예측*만을 제공한다. 그 결과, 여러 가능한 미래 시나리오 중 평균적인 결과를 예측하는 경향이 있으며, 이로 인해 예측 출력이 흐릿해지거나, 작은 규모의 중요 기상 패턴이 제대로 재현되지 않는 문제가 발생할 수 있다. 이러한 한계를 보완하기 위해, 향후에는 다중 시나리오 기반의 확률적 예측 모델로 확장하여 예측의 불확실성을 정량적으로 제공하는 방향이 제시되고 있다.
*결정론적 예측(deterministic prediction) : 입력이 같으면 항상 같은 예측 결과가 나오는 방식
2. 물리 기반 지식의 부재
Earthformer는 순전히 데이터 기반으로 설계되어, 지구 시스템의 물리 법칙이나 도메인 지식을 직접 반영하지 않는다. 최근에는 딥러닝 모델에 물리적 제약을 추가하거나, 딥러닝과 물리 기반 모델을 앙상블 형태로 결합하는 연구들이 활발히 진행되고 있으며, 이러한 접근이 예측 성능 향상에 효과적이라는 결과도 보고되고 있다. 따라서 Earthformer 역시 물리 모델과의 융합을 통해 신뢰성과 정확도를 더욱 높일 수 있을 것으로 기대된다.
3. 일반화 성능 검증의 필요성
다양한 기상·기후 데이터셋에 대한 추가 실험과 교차 검증을 통해, Earthformer의 일반화 성능을 평가하고 개선하는 연구도 함께 이어질 필요가 있다.
'🤖 ai logbook' 카테고리의 다른 글
| [paper] MedFuse: 임상 시계열 데이터와 흉부 X-ray 영상을 활용한 다중모달 모델 (0) | 2025.04.27 |
|---|---|
| [paper, NeurIPS 2023] PreDiff: 시공간 Diffusion Model 기반 기상·기후 예측모델 (1) | 2025.04.24 |
| [paper, NeurIPS 2023] CrossViViT : 시공간 정보를 활용한 태양복사량 시계열 예측 모델 (0) | 2025.04.12 |
| Simpson’s Paradox - 통계의 거짓말 (0) | 2025.02.19 |
| [paper] DeepSeek-R1 정리 및 Ollama를 이용해서 DeepSeek-R1 모델 간단하게 사용해보기 (0) | 2025.02.10 |
| [RL] MDP - Bellman equation (0) | 2024.06.25 |
| [RL] 마르코프 결정 과정 (Markov decision processes, MDP) (0) | 2024.06.23 |
| [RL] 강화 학습(Reinforcement Learning) (0) | 2024.06.23 |