paper : https://arxiv.org/abs/2306.01112
github : https://github.com/gitbooo/CrossViVit
태양 에너지는 탄소 배출을 줄여 기후 변화에 대응하는 데 중요한 역할을 하는 대표적인 재생 가능 에너지다. 그러나 수평면 태양복사량(Global Horizontal Irradiance, GHI)*은 구름의 양이나 기상 조건 등에 따라 변동성이 크기 때문에, 태양광 발전을 전력망에 안정적으로 통합하는 데 어려움이 따른다.
기존의 태양복사량 예측 연구들은 주로 단순한 시계열 데이터를 기반으로 미래 값을 추정해 왔지만, 이러한 방법은 주변의 구름 분포나 기상 상황과 같은 공간적 맥락을 충분히 반영하지 못해 예측 정확도에 한계가 있다.
태양복사량 예측의 정확도를 높이는 것은 전력망의 안정성과 운영 효율성을 크게 향상할 수 있기 때문에, 시공간 정보를 통합한 새로운 예측 기법의 필요성이 대두되고 있다.
*수평면 태양복사량(Global Horizontal Irradiance, GHI) : 태양으로부터 지구의 수평면에 도달하는 총 태양 복사 에너지의 양
CrossViViT
위성 이미지 등 시공간 정보를 활용하여 하루 전 태양복사량 예측 정확도를 향상시키기 위해 개발된 모델
모델 구조

해당 논문은 태양 복사량의 일일 예측을 개선하기 위해 CrossViViT라는 새로운 딥러닝 모델을 제안한다.
CrossViViT는 Multimodal neural network architecture로, 시간적 패턴과 공간적 정보를 동시에 고려해 보다 정확한 예측을 수행한다.
1. ctx* → patch → VisionTransformer
→ latent_ctx [BT, N, D]*
2. ts* → Linear Embedding → Transformer
→ latent_ts [B, T, D]*
3. latent_ctx + latent_ts → CrossTransformer
→ updated latent_ts (ctx 기반 시계열 특성 포함)
4. updated latent_ts → Transformer (Temporal Transformer)
→ 최종 시계열 예측 결과
5. MLP Heads + Quantile Mask
→ 최종 출력 (예측값), 마스크, attention 스코어
* ctx: context image, 위성 이미지 같은 공간 정보
ts: time series
latent_ctx: context 이미지를 Vision Transformer에 통과시켜 얻은 잠재 표현(latent representation).
크기는 [BT, N, D]
([여러 시간 프레임의 이미지를 포함한 배치, 한 이미지가 나뉜 patch의 개수, 임베딩 차원 수(각 벡터가 갖는 feature의 크기)])
latent_ts: 시계열 데이터를 Transformer에 통과시켜 얻은 잠재 표현.
크기는 [B, T, D]
([배치 크기, 시계열의 길이, 임베딩 차원 수])
Vision Transformer
self.ctx_encoder = VisionTransformer(
dim, depth, heads, dim_head, dim * mlp_ratio, image_size, dropout, pe_type == "rope", use_glu
)
- 컨텍스트 프레임(비디오)을 인코딩하는 Vision Transformer (ViT)
- Self-Attention을 통해 프레임 간의 공간적 관계 학습
init()
def __init__(...):
self.blocks = nn.ModuleList([])
for _ in range(depth):
self.blocks.append(
nn.ModuleList([
PreNorm(dim, SelfAttention(...)),
PreNorm(dim, FeedForward(...)),
])
)
- depth 만큼 반복되는 Transformer Block 리스트 구성
- 각각의 Block은 Self-Attention*, FeedForward로 구성
- 두 연산 모두 PreNorm(LayerNorm 사전 적용)으로 감쌈. x = x + Attention(LayerNorm(x))
* Self-Attention : 입력 시퀀스 내에서 단어(또는 토큰)들끼리 서로 얼마나 관련이 있는지 계산하는 메커니즘
forward()
def forward(self, src, src_pos_emb):
for i in range(len(self.blocks)):
sattn, sff = self.blocks[i]
out, sattn_scores = sattn(src, pos_emb=src_pos_emb)
src = out + src
src = sff(src) + src
- 입력 src에 대해 Block을 순차적으로 적용
- 각 Block은 Residual 구조 (출력 + 입력)
* Residual 구조 : 정보 손실을 막고, 기울기 소실 방지하기 위해 입력을 출력에 더해주는 구조
시계열 인코더 (Transformer)
self.ts_encoder = Transformer(
dim, ts_length, depth, heads, dim_head, dim * mlp_ratio, dropout=dropout
)
- 시계열 데이터를 인코딩하는 Transformer
- 시간적 특성을 학습하기 위해 사용됨
init()
def __init__(...):
self.pos_embedding = nn.Parameter(torch.randn(1, num_frames, dim))
for _ in range(depth):
self.layers.append(
nn.ModuleList([
PreNorm(dim, Attention(...)),
PreNorm(dim, FeedForward(...)),
])
)
- num_frames만큼의 위치 임베딩 (pos_embedding) 추가
- 기본적인 Attention → FFN 구조 반복
- 전반적으로 Vision Transformer와 구조적으로 유사 (입력 타입만 다름)
forward()
def forward(self, x):
x += self.pos_embedding
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return self.norm(x)
- 입력 시퀀스에 위치 임베딩을 더함
- 각 Layer에 대해 Attention, FFN 적용 + Residual 연결
- 마지막에 LayerNorm (입력을 정규화 (평균 0, 표준편차 1))
CrossTransformer
self.mixer = CrossTransformer(
dim, depth, heads, dim_head, dim * mlp_ratio, image_size, dropout, pe_type == "rope", use_glu
)
- Cross-Attention*을 통해 시계열 데이터 (ts)가 컨텍스트 데이터(ctx)에서 정보를 추출.
* Cross-Attention : Self-Attention과 동작은 동일하나, 두개의 다른 input sequence를 mix하고 조합
init()
def __init__(...):
for _ in range(depth):
self.cross_layers.append(
nn.ModuleList([
CrossPreNorm(dim, CrossAttention(...)),
PreNorm(dim, FeedForward(...)),
])
)
- 각 Layer는 Cross-Attention, FFN로 구성
forward()
def forward(self, src, tgt, src_pos_emb, tgt_pos_emb):
for cattn, cff in self.cross_layers:
out, cattn_scores = cattn(src, src_pos_emb, tgt, tgt_pos_emb)
tgt = out + tgt
tgt = cff(tgt) + tgt
- tgt가 src를 바라보며 Cross-Attention 수행
- 이후 FFN → Residual → 다음 레이어로 전달
Temporal Transformer (Decoder)
self.temporal_transformer = Transformer(
decoder_dim, ts_length, decoder_depth, decoder_heads, decoder_dim_head, decoder_dim * mlp_ratio, dropout=dropout
)
- 최종 시계열 예측을 위한 Transformer
- CrossTransformer에서 출력된 시계열 데이터를 최종 변환
- 일반적인 Transformer Decoder Layer와 유사하되, CrossTransformer 출력에만 집중
MLP Prediction Head
self.mlp_heads = nn.ModuleList([])
for i in range(num_mlp_heads):
self.mlp_heads.append(
nn.Sequential(
nn.LayerNorm(decoder_dim),
nn.Linear(decoder_dim, out_dim, bias=True),
nn.ReLU(),
)
)
- 최종 시계열 예측값을 생성하는 MLP 헤드
- num_mlp_heads 개수만큼 여러 개의 독립적인 예측 헤드가 존재하게 됨 -> 예측하려는 분위수(quantiles)의 개수
[최종] CrossViViT
init()
self.to_patch_embedding = ...
self.ctx_encoder = VisionTransformer(...)
self.ts_encoder = Transformer(...)
self.mixer = CrossTransformer(...)
self.temporal_transformer = Transformer(...)
self.mlp_heads = nn.ModuleList([...])
- 영상 처리: to_patch_embedding, ctx_encoder (VisionTransformer)
- 시계열 인코딩: ts_encoder
- 융합 (영상 + 시계열): mixer (CrossTransformer)
- 시계열 디코딩: temporal_transformer
- 최종 예측: mlp_heads
forward()
# 1. 시간 좌표 추가
ctx = torch.cat([ctx, time_coords], axis=2)
ts = torch.cat([ts, time_coords[..., 0, 0]], axis=-1)
# 2. 영상 → 패치 임베딩
ctx = rearrange(ctx, "b t c h w -> (b t) c h w")
ctx = self.to_patch_embedding(ctx)
# 3. Positional Embedding + 마스킹
ctx += pe_ctx
ctx_masked = self.random_masking(ctx, p)
# 4. VisionTransformer 인코딩
latent_ctx, self_attention_scores = self.ctx_encoder(ctx, src_pos_emb)
# 5. 시계열 처리 + Transformer 인코딩
ts = self.ts_embedding(ts)
ts_masked = self.random_masking(ts, p)
latent_ts = self.ts_encoder(ts)
# 6. Cross-Attention: 시계열 ← 영상
latent_ts, cross_attention_scores = self.mixer(latent_ctx, latent_ts, ...)
# 7. Temporal Transformer
y = self.temporal_transformer(latent_ts)
# 8. MLP를 통한 다중 헤드 예측
outputs = [mlp(y) for mlp in self.mlp_heads]
이 모델의 주요 특징은 다음과 같다
- 시계열 데이터(예: 이전 일자의 태양 복사량 시간 변화)와 인공위성 영상 데이터(예: 구름 분포 등의 공간 정보)를 결합하여 입력으로 사용한다. 이를 통해 단순 시계열만 볼 때 놓칠 수 있는 주변 기상 상황까지 모델이 학습할 수 있다.
- 모델에 ROtary Positional Encoding 기법(RoPE, 상대적 위치 인코딩)을 적용하여 시공간 데이터의 상대적인 위치 정보를 반영한다. 시간적 순서나 위성 영상 내 위치에 따른 영향력을 효과적으로 포착해 예측 정확도를 높인다.
- 하나의 확정적인 값만 예측하는 대신, 퀀타일 별 예측을 수행해 예측 결과의 불확실성을 정량화한다. 예를 들어, 10%, 50%, 90%와 같은 여러 퀀타일에 대한 태양 복사량을 예측하고, 이를 통해 신뢰 구간 형태의 예측치를 제공한다. 전력 운영자는 이 정보를 바탕으로 최악·최선 시나리오를 고려한 결정을 내릴 수 있어, 보다 신뢰할 수 있는 예측이 가능하다.
데이터셋 구성
SunLake라는 멀티모달 데이터셋을 사용함

해당 논문에서 고려한 6개의 기상 관측소 위치를 나타낸 것. 빨간 테두리는 분석에 사용된 공간 범위를 표시하며, TAM 관측소는 이 범위 밖에 위치한다. 또한, 분석에 활용된 11개의 스펙트럼 채널 중에서 IR_108, VIS_008, WV_073 세 가지 채널이 강조되어 있다. 이들은 각각 적외선(10.8 µm), 가시광선(0.8 µm), 수증기 채널(7.3 µm)에 해당한다.
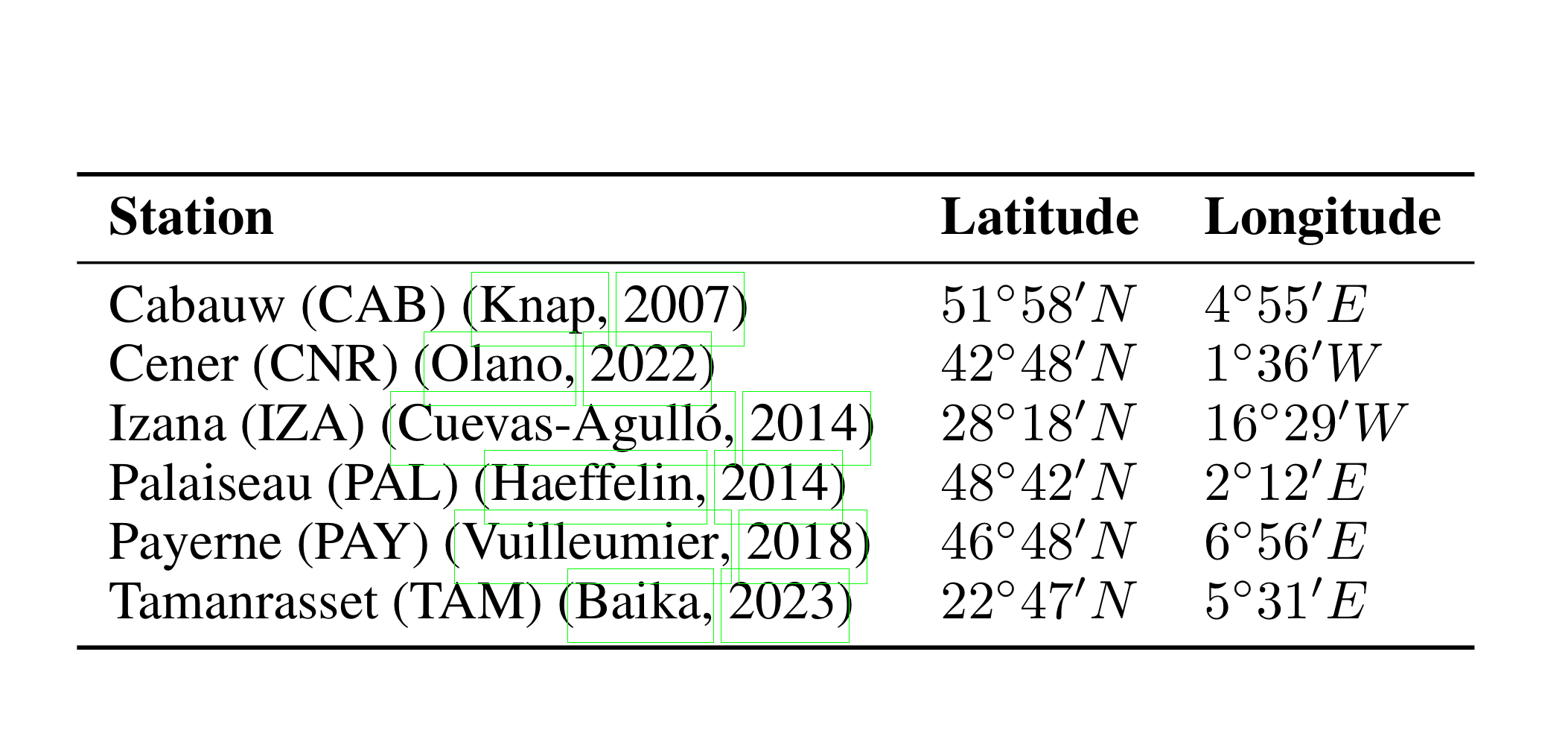
논문에서 사용한 각 관측소의 지리적 좌표와 고도 정보를 정리한 내용
CrossViViT 모델의 학습과 평가는 방대한 기간과 다양한 지역을 아우르는 Multi Modal 데이터셋을 기반으로 수행되었다.
이 데이터셋은 다음과 같은 요소들로 구성되어 있다.
| 항목 | 내용 |
| Temporal Span (시간 범위) | 2008년 ~ 2022년 |
| Temporal Resolution (시간 해상도) | 30분 간격 |
| Spatial Span (공간 범위) | 남서: [-21.34, 24.98], 북동: [19.53, 65.85](북아프리카 ~ 유럽 남부를 커버하는 위경도 영역) |
| Spatial Resolution | 약 48–72 km/pixel (512x512 -> 64×64 해상도로 다운샘플링) |
| 분류 | 채널 수 | 파장 (Wavelength) | 특징 |
| 적외선 (Infrared) | 7개 | 16μm, 39μm, 87μm, 97μm, 108μm, 120μm, 134μm | 구름, 지표, 야간 정보 포착 |
| 가시광 (Visible) | 2개 | 600nm, 800nm | 낮 시간대의 태양 복사 및 표면 반사율 |
| 수증기 (Water Vapor) | 2개 | 62μm, 73μm | 대기 중 수증기량 탐지 |
- 관측 기간: 2008년부터 2022년까지 총 14년에 걸친 데이터를 활용했다. 이렇게 긴 기간의 데이터를 통해 모델은 연간 주기성과 같은 장기 패턴까지 학습할 수 있다.
- 측정 위치: 지리적 조건이 다양한 6개의 태양 복사량 측정소에서 데이터를 수집했다. 각 측정소는 서로 다른 기후 및 환경 조건을 갖고 있기 때문에, 모델은 여러 지역에 걸쳐 일반화된 예측 능력을 학습할 수 있었다.
- 데이터 유형: 인공위성 영상, 기상 관측 데이터(예: 기온, 습도, 풍속 등), 태양 복사량의 지상 측정 데이터를 통합하여 사용했다. 이러한 시공간 데이터의 결합을 통해, 모델은 태양 복사량에 영향을 미치는 복합적인 요인들을 동시에 고려할 수 있게 된다.
실험 및 결과
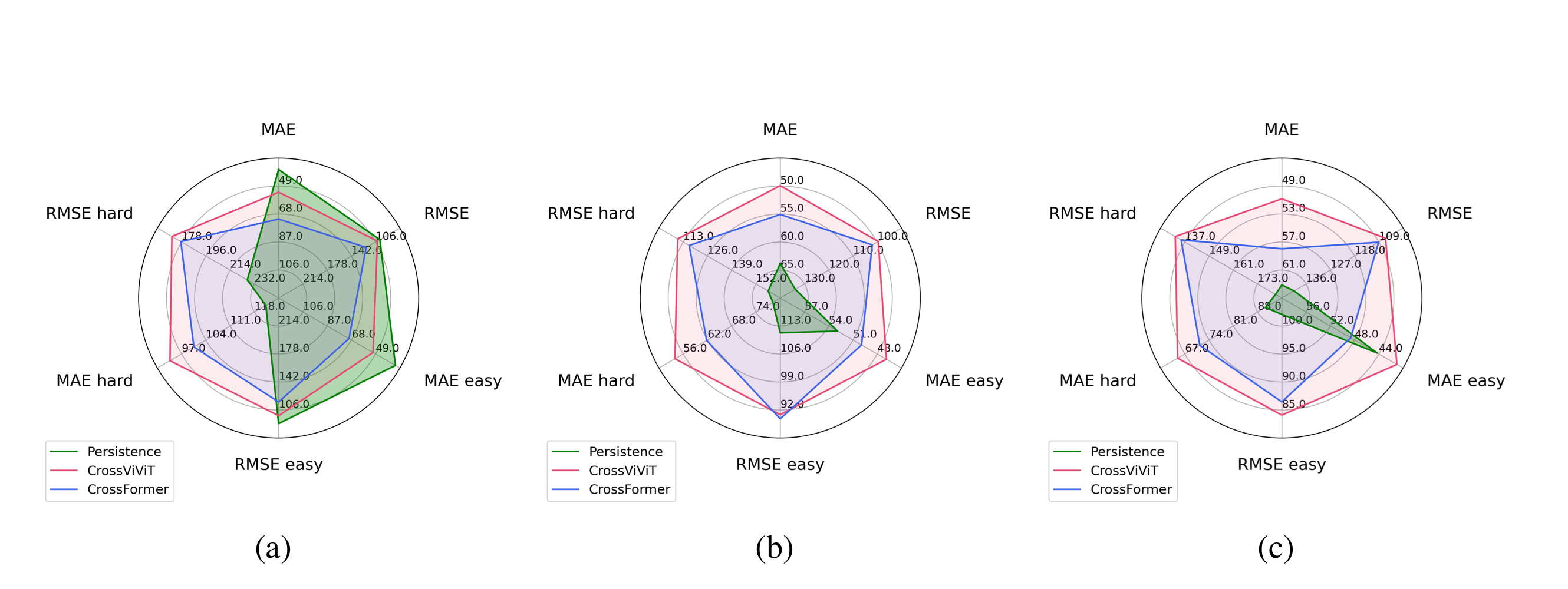
위 레이더 플롯은 CrossViViT 모델의 성능을 Persistence 모델 및 CrossFormer 모델과 비교한 결과를 나타낸다.
학습에 사용된 기간인 2008년부터 2016년까지의 기간을 기준으로, 학습에 포함되지 않은 관측소인 TAM(a), CAB(b), PAY(c)에 대해 평가를 진행하였다.
CrossViViT는 다양한 조건에서 예측할 때 CrossFormer보다 더 뛰어난 유연성을 보여주는 것으로 나타났으며, Persistence 모델은 특히 ‘어려운(Hard)’ 날의 조건에서 예측 정확도가 크게 떨어지는 경향을 보였다고 한다.
* MAE (Mean Absolute Error) : 실제 값과 예측 값 사이의 절대값 차이들의 평균. 모델이 평균적으로 얼마만큼 예측을 틀렸는가를 의미.
예: MAE가 20이라면, 평균적으로 예측값이 실제값에서 20만큼 벗어났다는 뜻.
모든 오차를 동일하게 취급하며, 이상치(outlier)에 덜 민감함
RMSE (Root Mean Squared Error) : 실제 값과 예측 값 사이의 차이를 제곱해서 평균을 낸 후, 그 평균에 루트를 씌운 값. 오차가 클수록 훨씬 더 크게 반영되므로, 큰 오차(=심한 예측 실패)에 더 민감하게 반응.
오차가 클수록 더 큰 패널티를 줌, 이상치(outlier)에 민감
해당 논문에서는 모델의 성능을 보다 면밀히 검증하기 위해 새로운 테스트 평가 방식을 도입했다. 예를 들어, 맑은 날과 흐린 날처럼 서로 다른 기상 조건에 따라 테스트 데이터를 나누고, 각각의 상황에서 모델이 얼마나 잘 예측하는지를 따로 평가했다.
그 결과 CrossViViT는 맑은 날뿐만 아니라 구름량이 시시각각 변하는 복잡한 조건에서도 안정적으로 높은 정확도를 유지하는 것으로 나타났다.
학습 중 한 번도 관측되지 않았던 새로운 지역에 대해서도 예측 실험을 진행했다.
그 결과 CrossViViT는 낯선 지역의 태양 복사량에 대해서도 합리적인 수준의 예측 정확도를 보여주었다.
이러한 실험은 일종의 zero-shot 일반화 테스트*로 볼 수 있으며, CrossViViT가 지리적 조건이 달라지더라도 충분히 적용 가능하다는 가능성을 보여줬다.
*zero-shot 일반화 테스트 : 모델이 학습 중 한 번도 본 적 없는 새로운 상황이나 데이터에 대해 얼마나 잘 작동하는지를 평가하는 방법
한계점 및 향후 연구 방향
- 데이터 범위의 한계 : 현재는 6개 지역의 데이터만으로 검증이 이루어졌지만, 보다 다양한 기후대와 지리적 조건을 포함한 데이터를 활용함으로써 모델의 보편성과 확장 가능성을 높일 필요가 있다. 예를 들어, 사막, 해안, 산악 지역처럼 기상 특성이 뚜렷이 다른 환경의 태양 복사량 데이터를 추가로 수집하고 학습에 반영해야 모델의 적용 범위가 넓어진다.
- 모델 학습 효율성의 문제 : 제안된 모델은 구조가 복잡해 학습에 상당한 시간이 소요되며, 실제로 GPU 한 개 (RTX8000) 기준으로 약 5시간 정도의 훈련 시간이 필요하다. 보다 실용적인 활용을 위해서는 학습 속도를 개선하거나, 모델을 경량화해 연산 효율을 높이는 방향의 연구가 뒤따라야 한다.
- 정규화 및 전처리 기법 보완 : 현재 사용된 전처리 및 학습 기법 외에도, 과적합을 줄이고 모델의 일반화 성능을 향상할 수 있는 새로운 정규화 방식이나 데이터 증강 기법 등을 도입할 필요가 있다.
'🤖 ai logbook' 카테고리의 다른 글
| [paper, ICML 2020] REALM(Retrieval-Augmented Language Model Pre-Training) (1) | 2025.04.30 |
|---|---|
| [paper] MedFuse: 임상 시계열 데이터와 흉부 X-ray 영상을 활용한 다중모달 모델 (0) | 2025.04.27 |
| [paper, NeurIPS 2023] PreDiff: 시공간 Diffusion Model 기반 기상·기후 예측모델 (1) | 2025.04.24 |
| [paper, NeurIPS 2022] Earthformer : 시공간 Transformer 기반 기상·기후 예측 모델 (0) | 2025.04.16 |
| Simpson’s Paradox - 통계의 거짓말 (0) | 2025.02.19 |
| [paper] DeepSeek-R1 정리 및 Ollama를 이용해서 DeepSeek-R1 모델 간단하게 사용해보기 (0) | 2025.02.10 |
| [RL] MDP - Bellman equation (0) | 2024.06.25 |
| [RL] 마르코프 결정 과정 (Markov decision processes, MDP) (0) | 2024.06.23 |