
엔비디아 주가 폭락을 겪으며, DeepSeek가 뭐하는 놈이길래 날 이렇게 아프게 하나 싶어 간단하게 공부한 내용 정리
DeepSeek에 대한 많은 논란은 제외
paper : https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1 : Nvidia 주가 폭락의 원인
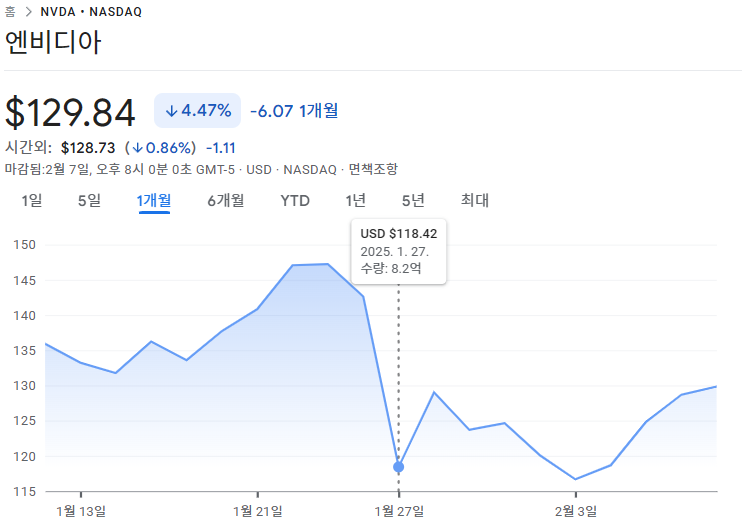
임시공휴일로 지정되었다고, 신난 직장인에게, 1월 27일은 꽤나 충격적인 하루 였다.
Nvidia의 주가가 17% 하락했다. 그리고 그 중심에는 DeepSeek-R1이라는 오픈소스 AI 모델이 존재했다.
DeepSeek-R1은 단순한 AI 텍스트 생성 모델이 아니라 논리적 추론(logical reasoning)에 특화된 모델이다.
기존의 모델들은 일반적으로 지도 학습(Supervised Fine-Tuning, SFT) 기반으로 훈련되지만, 이 논문(DeepSeek-R1)
에서는 순수한 강화 학습(RL)만을 사용하여 LLM의 추론 능력을 향상시키는 방법에 대해 제안하였다.
Nvidia가 위협받는 이유
- 기존 AI 모델들은 대량의 Nvidia GPU를 사용해야 했음.
- 하지만 DeepSeek-R1은 적은 GPU로도 높은 성능을 제공해버림.
- AI 기업들이 더 이상 Nvidia에 의존하지 않아도 되는 상황이 발생함.
DeepSeek 특징 키워드
1. 오픈소스 (open source) OpenAI도 해내지 못한 것
2. 투명한 AI 추론 과정 (the reasoning process)
3. 강화 학습 (Reinforcement Learning, RL)
4. 증류 (Distillation)
DeepSeek Model
- DeepSeek-R1-Zero: 지도 학습 없이 강화 학습만으로 학습된 모델.
- 기존에는 지도 학습(SFT)을 거친 후 강화 학습을 적용했지만, DeepSeek-R1-Zero는 처음부터 RL을 적용하여 학습.
- RL 과정에서 모델이 자율적으로 체인 오브 싱킹(Chain-of-Thought, CoT)을 탐색하며 발전.
- 기본 모델 : DeepSeek-V3-Base
- 사용한 RL 알고리즘 : Group Relative Policy Optimization (GRPO)
- 보상 모델(Reward Model) : 정확성 보상(Accuracy Reward) ➡ 정답 여부 확인, 형식 보상(Format Reward) ➡ 답변을 <think> </think> 태그로 감싸서 명확한 사고 과정을 유도.
- 자기 진화(Self-Evolution) :모델이 점점 더 긴 체인 오브 싱킹(CoT)을 사용하여 정답률을 향상.
- DeepSeek-R1: DeepSeek-R1-Zero의 단점을 보완하기 위해 Cold-Start 데이터를 추가하고, 다단계 학습을 거친 모델.
- DeepSeek-R1-Zero는 강력한 추론 능력을 가지지만, 가독성이 낮고 언어 혼합 현상이 발생.
- 이를 해결하기 위해 Cold-Start 데이터를 사용한 사전 미세 조정(SFT) 후 RL 적용하여 DeepSeek-R1 개발.
- Cold-Start 데이터 추가: 초기에 일부 지도 학습 데이터(긴 CoT 예제)를 사용하여 기본 모델 튜닝.
- 강화 학습 개선 : 언어 일관성 보상(Language Consistency Reward) 추가
- 거부 샘플링(Rejection Sampling) 및 추가 지도 학습(Supervised Fine-Tuning) : RL 후 생성된 데이터를 다시 지도 학습 데이터로 활용하여 최적화.
- Distilled Models: DeepSeek-R1의 성능을 작은 모델(1.5B~70B 파라미터)에 적용하여 고성능의 소형 모델을 개발.
- DeepSeek-R1의 강력한 추론 패턴을 Qwen 및 Llama 모델(1.5B~70B)로 distillation.
- 14B 모델이 기존 오픈소스 모델(QwQ-32B-Preview)보다 월등히 높은 성능을 기록.
- Qwen2.5 및 Llama 시리즈 모델(1.5B~70B)에 fine-tuning 진행한 결과, RL 없이도 distillation만으로도 뛰어난 성능을 확보하는 것을 확인하였음.
❕
지도 학습 없이 강화 학습만으로 학습된 모델이라는 점에서 AlphaGo Zero를 떠올리는 사람들이 많다.
AlphaGo Zero는 인간이 제공한 데이터를 사용하지 않고(바둑기사의 기보 자료 없이), 바둑 규칙만을 학습하여 스스로 바둑을 익혀 기존 AlphaGo보다 훨씬 강한 모델로 발전했다.(자가 대국을 통해 스스로 학습)
AlphaGo Zero는 몬테카를로 트리 탐색(MCTS)과 강화 학습을 결합하여 최적의 수를 찾는 방식을 사용하였다.
DeepSeek와 OpenAI가 함께 언급되는 상황에서, DeepSeek가 실제로 참고하거나 전략으로 삼은 것은 AlphaGo Zero인 것 같기도 하다.
DeepSeek-R1 vs 기타 모델 벤치 마크 성능 비교
| 벤치마크 | DeepSeek-R1 | OpenAI-o1-1217 | GPT-4o |
| AIME 2024 (Math) | 79.8% | 79.2% | 9.3% |
| MATH-500 (Math) | 97.3% | 96.4% | 74.6% |
| GPQA Diamond (General) | 71.5% | 75.7% | 49.9% |
| Codeforces (Code) | 96.3% | 96.6% | 23.6% |
| SWE Verified (Code) | 49.2% | 48.9% | 38.8% |
➡ DeepSeek-R1은 OpenAI-o1-1217과 유사한 성능을 달성하며, 특히 수학 및 코딩 분야에서 뛰어난 성능을 보임.

DeepSeek-R1-Zero 성능 비교

Distilled Model 성능 비교
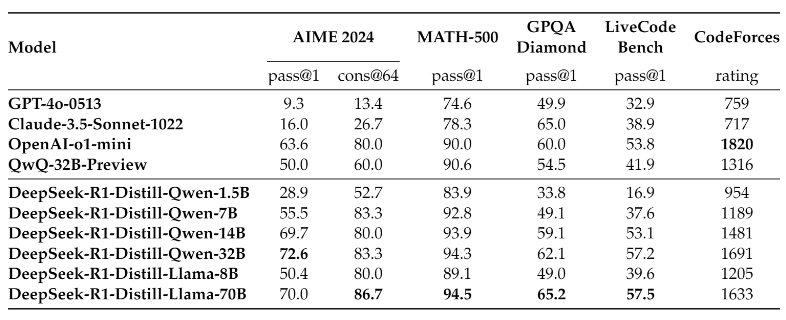
➡ Distilled 모델도 경쟁력 있는 성능을 보이며, 특히 14B 모델이 기존 QwQ-32B-Preview 모델보다 좋은 성능을 보임
Ollama를 이용해 DeepSeek-R1 모델 사용해보기
먼저, Ollama 설치하기 ➡ https://ollama.com/download
pip install ollama
DeepSeek-R1 모델 다운로드하기 ➡ https://ollama.com/library/deepseek-r1
# DeepSeek-R1 모델 다운로드
ollama.pull('deepseek-r1:7b')
간단하게 Ollama를 이용하여 DeepSeek-R1 모델 실행
import ollama
# DeepSeek-R1 실행 및 질문하기
response = ollama.chat(model='deepseek-r1:7b', messages=[
{"role": "system", "content": "You are an AI assistant that provides detailed reasoning before answering."},
{"role": "user", "content": "DeepSeek-R1은 어떻게 동작하나요? 추론 과정을 명확하게 보여주세요."}
])
# 응답 출력
full_response = response['message']['content']
print(full_response)<think>
Okay, I'm trying to understand how DeepSeek-R1 works. From what I gather, it's an AI developed by DeepSeek. I know that many AI models use something called a transformer architecture, which is pretty common these days, like in BERT or GPT. So maybe DeepSeek-R1 uses transformers too. Transformer architecture involves token embeddings and positional encodings. Each word or token is converted into an embedding vector, and then positional encodings add information about their position in the sequence. That makes sense because it helps the model understand the context of each word relative to others. The model has multiple layers stacked together. These layers include self-attention mechanisms and feed-forward neural networks. Self-attention allows the model to weigh the importance of different words in the sentence when processing each word, which is crucial for understanding relationships between words. The multi-head attention part means that the model can look at different aspects of the input simultaneously, providing more flexibility. Then there's the feed-forward network after the attention layers. This helps the model learn more complex representations by applying non-linear transformations. The idea is that this deeper structure allows the model to capture intricate patterns in the data. For training, DeepSeek-R1 probably uses a similar approach to other transformers. They are pre-trained on a large corpus of text to learn general language patterns and then fine-tuned for specific tasks like translation or text generation. The masked language modeling objective is common, where some tokens are randomly removed, and the model has to predict them, which helps in learning rich representations. Tokenization and decoding are also important parts. Tokens break down text into manageable pieces, and during inference, the model generates text one token at a time using beam search or other decoding strategies. Beam search is a way to generate more accurate sequences by considering multiple possibilities at each step. I'm not entirely sure about all the hyperparameters mentioned, like learning rates and batch sizes. These would affect how the model trains and its performance. The learning rate determines how big the steps are when the model updates its weights, while the batch size affects the amount of data processed in each update. Smaller batches can be computationally expensive but might help with generalization. Pre-training is a big part of training large models. It involves tasks like masked language modeling, where the model predicts missing words in a sentence. This helps it understand the context and relationships between words. Fine-tuning then adapts this pre-trained knowledge to specific tasks, making the model more effective for downstream applications. I'm curious about how DeepSeek-R1 handles different types of inputs compared to BERT or GPT. Do they use similar tokenization? I think most transformers do, using their own vocabularies or adapting existing ones like Chinese models might be based on RoBERTa's approach. Also, the attention mechanism in transformers is scaled by the square root of the number of dimensions. This scaling helps prevent gradients from becoming too large when passing through many layers, which is something I read about in the original transformer paper. The multi-head aspect means that each head focuses on different aspects of the input data. For example, some heads might capture syntactic relationships while others handle semantic ones. This diversity can improve the model's understanding of complex texts. In the training process, besides masked language modeling, are there other tasks? Maybe next sentence prediction or classification tasks to help with learning. Fine-tuning on these can make the model better at specific applications like sentiment analysis or question answering. I wonder about inference speed. Transformers can be slow during generation because they have to process each token sequentially. Optimization techniques likejit or using hardware acceleration might help speed things up, but I'm not sure how DeepSeek-R1 handles that. Model compression and efficiency are also considerations. Larger models require more computational resources, so maybe DeepSeek-R1 uses pruning or quantization to reduce size without losing much performance. This would make it more accessible for deployment on edge devices or in scenarios with limited resources. Lastly, interpretability is a key concern for many users. How do people understand what the model is doing? Tools like attention visualization can help, showing which parts of the input are most influential in generating each output token.
</think>
DeepSeek-R1 is an advanced AI model developed by DeepSeek, utilizing the transformer architecture to process and generate text efficiently. Here's a detailed breakdown of its operation: 1. **Transformer Architecture**: - **Token Embeddings and Positional Encodings**: Each input word or token is converted into an embedding vector. These vectors are augmented with positional encodings to convey their context within the sequence. - **Multi-Layer Structure**: The model consists of multiple layers, each containing self-attention mechanisms and feed-forward neural networks. Self-attention allows the model to weigh the importance of different words dynamically, while multi-head attention enhances flexibility by examining various input aspects simultaneously. 2. **Self-Attention Mechanism**: - This mechanism enables the model to understand relationships between words, crucial for context comprehension. Each head in multi-head attention focuses on different aspects, improving the model's analytical depth. 3. **Feed-Forward Networks**: - These layers apply non-linear transformations post-attention, enabling the model to capture complex patterns and intricate data structures. 4. **Training Process**: - Pre-trained on a vast corpus for language patterns using masked language modeling (MLM), where tokens are removed and predicted. This pre-training is followed by fine-tuning for specific tasks like translation or text generation. - Common hyperparameters include learning rates, batch sizes, and the number of epochs, influencing convergence and model performance. 5. **Tokenization and Decoding**: - Text is broken into manageable tokens using tokenization techniques similar to BERT or GPT. - During inference, beam search decoding strategies generate text by exploring multiple possibilities at each step for accuracy. 6. **Pre-Training and Fine-Tuning**: - Pre-training on tasks like masked LM helps in learning general language representations, while fine-tuning adapts the model to specific applications, enhancing task-specific performance. 7. **Considerations Beyond Training**: - **Inference Speed**: Techniques like JIT (Just-In-Time) compilation or hardware acceleration may optimize generation speed. - **Model Efficiency**: Compression methods such as pruning or quantization are employed for deployment on edge devices or resource-limited settings. - **Interpretability**: Tools like attention visualization aid in understanding the model's decision-making process. In summary, DeepSeek-R1 is a powerful transformer-based model that efficiently processes text through layers of self-attention and feed-forward networks, pre-trained for general language tasks and fine-tuned for specific applications. Its modular architecture allows for flexibility and scalability, addressing various computational and deployment needs effectively.
import ollama
response = ollama.chat(model='deepseek-r1:7b', messages=[
{"role": "system", "content": "You are an AI assistant that provides detailed reasoning before answering."},
{"role": "user", "content":
"If I invest 10 million won in a 3% interest product per year, how much can I earn per month (Tax is 15.4%)?"
}
])
full_response = response['message']['content']
print(full_response)<think>
First, I need to calculate the annual interest from the investment of 10 million won at a 3% interest rate. Next, I'll compute the tax on this annual interest by applying the 15.4% tax rate. After determining the taxable amount, I'll subtract the tax to find out the net annual interest income. Finally, I'll convert the net annual interest into a monthly figure by dividing it by 12.
</think>
**Solution:** Let's break down the problem step by step to determine how much you can earn per month from your investment after taxes. ### **Step 1: Calculate the Annual Interest Earned** You are investing **10,000,000 won** at an annual interest rate of **3%**. \[ \text{Annual Interest} = \text{Principal} \times \text{Interest Rate} \] \[ \text{Annual Interest} = 10,000,000 \times 0.03 = 300,000 \text{ won/year} \] ### **Step 2: Calculate the Tax on Annual Interest** The tax rate is **15.4%**. \[ \text{Tax} = \text{Annual Interest} \times \text{Tax Rate} \] \[ \text{Tax} = 300,000 \times 0.154 = 46,200 \text{ won/year} \] ### **Step 3: Determine the Net Annual Interest Income** Subtract the tax from the annual interest to get the net income. \[ \text{Net Annual Interest} = \text{Annual Interest} - \text{Tax} \] \[ \text{Net Annual Interest} = 300,000 - 46,200 = 253,800 \text{ won/year} \] ### **Step 4: Calculate the Monthly Net Interest Income** Divide the net annual interest by 12 to get the monthly earnings. \[ \text{Monthly Interest} = \frac{\text{Net Annual Interest}}{12} \] \[ \text{Monthly Interest} = \frac{253,800}{12} = 21,150 \text{ won/month} \] ### **Final Answer:** You can earn approximately \(\boxed{21,\!150}\) won per month after taxes.
마무리하며,
중국이 AI를 잘한다는 사실은 (특히, 그들의 cctv 안면인식 기술) 이미 잘 알고 있었지만,
그래도 미국이 AI 분야에서는 압도적인 1위를 차지하고 있다고 생각하고 있었다.
하지만, 이번 DeepSeek로 인한 파장을 봤을 때, DeepSeek의 기술력 자체보다도(물론 놀랍지만) 중국의 AI 기술 발전 속도가 예상보다 훨씬 빠르다는 사실에 더 큰 충격을 받았다.
미국과 중국의 AI 경쟁이 심화되는 가운데, 한국은 이 싸움에 제대로 참여하지 못하고 있는 현실이 안타깝다.
'🤖 ai logbook' 카테고리의 다른 글
| [paper, NeurIPS 2023] PreDiff: 시공간 Diffusion Model 기반 기상·기후 예측모델 (1) | 2025.04.24 |
|---|---|
| [paper, NeurIPS 2022] Earthformer : 시공간 Transformer 기반 기상·기후 예측 모델 (0) | 2025.04.16 |
| [paper, NeurIPS 2023] CrossViViT : 시공간 정보를 활용한 태양복사량 시계열 예측 모델 (0) | 2025.04.12 |
| Simpson’s Paradox - 통계의 거짓말 (0) | 2025.02.19 |
| [RL] MDP - Bellman equation (0) | 2024.06.25 |
| [RL] 마르코프 결정 과정 (Markov decision processes, MDP) (0) | 2024.06.23 |
| [RL] 강화 학습(Reinforcement Learning) (0) | 2024.06.23 |
| [RL] 간단한 OpenAI Gym 튜토리얼 (CartPole) (0) | 2023.08.28 |