[IBM AI course #2] Introduction to Deep Learning & Neural Networks with Keras
Gradient Descent
신경망이 가중치(w)와 편향(b)을 학습하고 최적화하는 방식을 이해하는 데 필수적인 개념.
예를 들어,
[ z = 2x ]라는 데이터를 관찰했을 때, 우리는 [ wx ]가 실제값 z와 최대한 비슷하게 나오도록 만들고 싶은 것이 핵심이다. 여기서 w는 우리가 학습할 가중치(weight)가 된다.
| x | z (= 2x) |
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
손실 함수 (Cost/Loss Function)
w 값을 최적화하여 데이터에 가장 잘 맞는 직선을 찾는 것.
손실 함수 J(w) = ∑ (z - wx)²로 정의했을 때 (평균 제곱 오차 (MSE) 구조)
이 함수는 포물선 형태로, 하나의 전역 최솟값(global minimum)을 가짐.
예시에서 최적의 w = 2일 때 손실이 최소가 된다.
| w 값 | 예측값 wx (x=1,2,3) | 오차² (각 항의 제곱) | 손실 함수 J(w) = ∑ (z - wx)² |
| 1.0 | 1, 2, 3 | (2-1)² + (4-2)² + (6-3)² = 1 + 4 + 9 | 14 |
| 1.5 | 1.5, 3.0, 4.5 | (2-1.5)² + (4-3)² + (6-4.5)² = 0.25 + 1 + 2.25 | 3.5 |
| 2.0 | 2, 4, 6 | (2-2)² + (4-4)² + (6-6)² = 0 + 0 + 0 | 0 (최소) |
| 2.5 | 2.5, 5.0, 7.5 | (2-2.5)² + (4-5)² + (6-7.5)² = 0.25 + 1 + 2.25 | 3.5 |
| 3.0 | 3, 6, 9 | (2-3)² + (4-6)² + (6-9)² = 1 + 4 + 9 | 14 |
경사하강법 (Gradient Descent)
손실 함수 J(w)의 최솟값을 찾기 위한 반복적 최적화 알고리즘.
각 단계에서의 이동 방향은, 조금씩 w값을 조정하면서 현재 지점에서의 기울기(gradient)의 음수 방향으로 향함.
업데이트 식: w_new = w_old - learning_rate * gradient
*gradient : ∇J(w). 현재 w에서의 손실 함수의 기울기. 즉, ∇J(w)=−2x(z−wx)
학습률 (Learning Rate)
크면 → 큰 보폭으로 빠르게 이동 가능하지만, 최소값을 지나칠 위험 있음.
작으면 → 안정적이나 매우 느린 수렴.
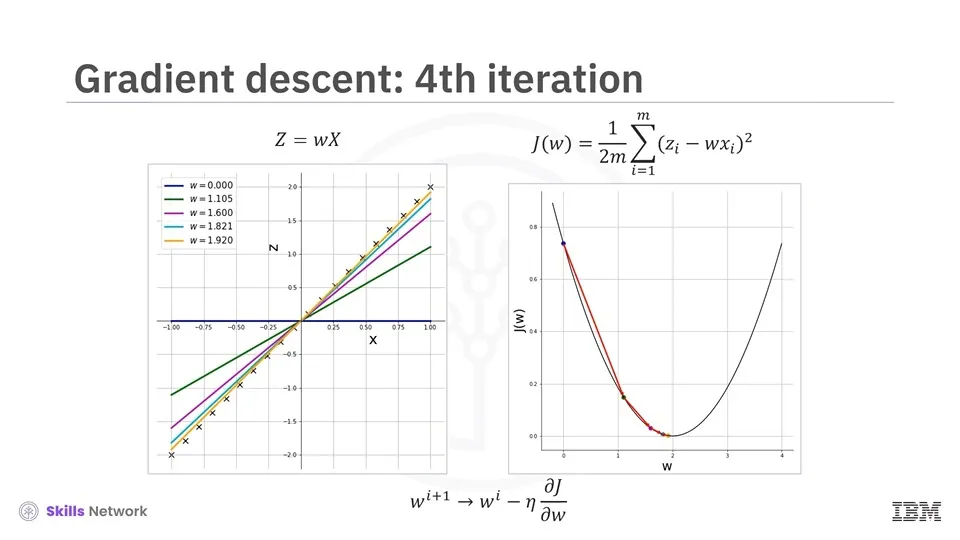
적용 과정 (Learning Rate = 0.4)
초기 가중치 w=0
→ 이때 모델의 예측값 wx는 항상 0이므로, 출력값 z는 0인 수평선이 된다.
→ 실제 데이터 z=2x와는 큰 차이를 보여서, 손실 함수의 값이 매우 크다.
1차 반복
→ 손실 함수의 기울기(gradient)가 크기 때문에, 경사하강법은 가중치를 크게 이동시킨다.
→ 이로 인해 예측선의 기울기가 급격히 변하면서, 손실이 크게 감소한다.
→ 모델이 눈에 띄게 더 나아진다.
2~4차 반복
→ 모델이 점점 정답에 가까워지면서, 손실 함수의 기울기(gradient)가 점점 작아진다.
→ 따라서 가중치의 변화 폭도 작아지고, 모델의 업데이트는 점진적으로 안정화된다.
→ 선형 모델의 기울기 w는 최적값인 2에 가까워지며, 데이터에 더 잘 맞게 된다.
반복이 계속될수록
→ 예측선은 실제 데이터 분포와 점점 더 잘 일치하게 되고,
→ 손실은 점점 작아지며,
→ 모델은 최적의 상태에 가까워진다.
→ 이 과정을 통해 선형 모델이 점점 데이터를 잘 설명하는 방향으로 적합(fitting) 되는 것이다.
결론
Gradient Descent는 함수의 최솟값을 반복적으로 찾아가는 알고리즘.
가중치 업데이트는 gradient의 음수 방향으로 이동하여 손실 최소화.
학습률(Learning Rate)의 설정은 수렴 속도와 정확성에 큰 영향을 미침.
직관적으로는 포물선 손실 함수에서 공을 굴려 내려가는 방식과 유사함.