[IBM AI course #1] Machine Learning with Python
Clustering
클러스터링은 데이터 간 유사성을 기반으로 그룹을 나누는 (고객 세분화, 이상치 탐지 등) 비지도 학습 기법이며,
K-Means, 밀도 기반 클러스터링(DBSCAN), 계층적 클러스터링 등 다양한 알고리즘이 존재한다.
K-Means 클러스터링
각 데이터 포인트를 가장 가까운 중심점(centroid)에 할당하며, 중심점을 반복적으로 업데이트한다.
클러스터 내 분산(Within-Cluster Variance) 최소화하는 것이 목표이며,
볼록(convex)이고 균형 잡힌 클러스터에 적합하다. (불균형하거나 복잡한 모양의 데이터에는 부적합.)
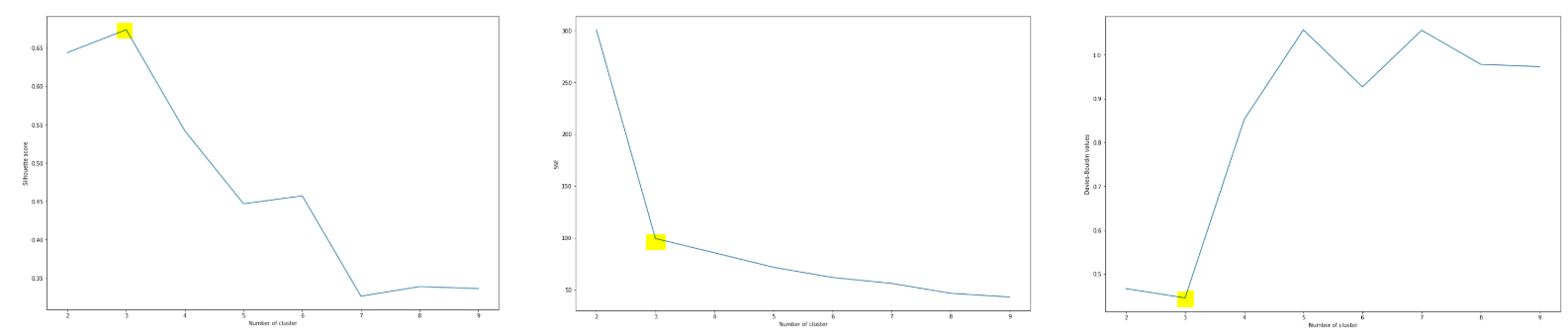
성능 평가 기법
Silhouette Score, Elbow Method, Davies-Bouldin Index
밀도 기반 클러스터링: DBSCAN & HDBSCAN
DBSCAN
사용자가 지정한 밀도 기준(eps, minPts)에 따라 클러스터 생성하는 알고리즘이다.
자연적이고 비정형적인 구조의 데이터에 적합하며, 클러스터에 속하지 않는 데이터 포인트는 노이즈(noise)로 구분이 가능하다.
반복(iterative) 구조는 아니다. (한번만 탐색)
단계
모든 포인트를 미분류 상태로 시작 (기본은 노이즈로 간주)
→ 각 포인트에 대해 이웃 탐색 (ε-반경 내 이웃 찾기). 반경 epsilon 내에 min_samples 개 이상의 포인트가 있다면, 그 포인트는 Core point (핵심점)으로 간주
→ Core point를 중심으로 이웃한 점들을 클러스터에 포함 (이웃 중에 다른 Core point가 있으면, 그 주변 이웃도 재귀적으로 포함시켜 클러스터를 확장)
→ 어떤 Core point의 ε-반경에도 속하지 않는 점은 Noise(잡음)로 최종 분류
vs K-means
| 항목 | K-means | DBSCAN |
| 클러스터 모양 | 구형/볼록 | 자유로운 형상 |
| 이상치 처리 | 불가 (무조건 클러스터 할당) | 가능 (노이즈로 분류) |
| 클러스터 수 지정 | 필수 (k 필요) | 불필요 |
HDBSCAN
DBSCAN의 확장판으로, 파라미터 없이 동작하며 클러스터 안정성(cluster stability)*을 기반으로 군집을 형성한다.
*클러스터 안정성: 거리 임계값 변화에 따라 클러스터가 얼마나 지속되는지를 측정.
방식
Agglomerative Clustering (병합형 계층 클러스터링) + Density-based Clustering (DBSCAN같은 밀도 기반 클러스터링)
단계
모든 포인트를 각자 하나의 클러스터(혹은 노이즈)로 시작
→ 밀도(density)가 높은 곳부터 시작해 밀도가 낮은 곳으로 내려가며 군집을 병합 (계층 구조(hierarchical tree) 생성)
→ 너무 불안정하거나 일시적인 클러스터는 제거하고 여러 밀도 수준에서 안정적으로 유지된 클러스터만 최종 선택
계층적 클러스터링
계층적 클러스터링은 덴드로그램을 생성하며, 방식에는 하향식(divisive/top-down)과 상향식(agglomerative/bottom-up)이 있다.
상향식은 작은 군집부터 병합해 가는 방식이며, 하향식은 전체 데이터를 점점 나눠가는 방식이다.
Dimension Reduction & Feature Engineering
차원 축소(Dimensionality Reduction)
주로 전처리 단계에서 데이터의 주요 정보를 유지하면서 특성(feature) 수를 줄이는 방법이다.
고차원 데이터를 더 낮은 차원으로 변환해 구조를 단순화하고, 시각화와 모델 성능에 도움을 준다.
대표적인 방법에는 PCA, t-SNE, UMAP이 있다.
PCA (Principal Component Analysis)
선형 방식, 데이터의 분산을 최대한 보존하며, 정보 손실 최소화(계산 효율 높음), 잡음 제거 효과.
→ 비선형 구조는 표현 불가
t-SNE (t-Distributed Stochastic Neighbor Embedding)
고차원 데이터를 저차원(2~3차원) 시각화에 적합 (비선형 구조 유지).
→ 느리고, 하이퍼파라미터에 민감하며, 전역 구조는 보존되지 않음.
UMAP (Uniform Manifold Approximation and Projection)
데이터의 다양체(manifold) 구조를 근사, 빠르고 안정적.
→ 구조 복잡, 해석 어려움
클러스터링 + 차원 축소 + 특성 선택
클러스터링, 차원 축소, 특성 선택은 모델 성능, 품질, 해석력을 높이는 데 함께 활용된다.
- 차원 축소는 클러스터링의 전처리로 활용 → 데이터 구조 단순화, 클러스터 품질 향상.
(예를 들어 얼굴 인식에서 PCA를 통해 Eigenfaces를 특성으로 사용할 수 있다) - 클러스터링을 통해 유사한 특성을 그룹화 → 중복 제거 가능
'🥇 certification logbook' 카테고리의 다른 글
| [Coursera/IBM course #2] Gradient Descent (0) | 2025.05.11 |
|---|---|
| [Coursera/IBM course #2] Neurons and Neural Networks & Artificial Neural Networks (0) | 2025.05.10 |
| [Coursera/IBM] Introduction to Deep Learning & Neural Networks with Keras 코스 소개 (1) | 2025.05.10 |
| [Coursera/IBM course #1] Evaluating and Validating Machine Learning Models (0) | 2025.05.10 |
| [Coursera/IBM course #1] Supervised Learning Models (2) | 2025.05.04 |
| [Coursera/IBM course #1] Linear Regression & Logistic Regression (0) | 2025.05.04 |
| [Coursera/IBM course #1] Scikit-Learn Machine Learning Ecosystem (0) | 2025.05.03 |
| [Coursera/IBM course #1] Tools for Machine Learning (1) | 2025.05.03 |