
Reference
- <파이썬 한권으로 끝내기>, 데싸라면▪빨간색 물고기▪자투리코드, 시대고시기획 시대교육
Scaling 메서드
scikit-learn의 perprocessing
https://scikit-learn.org/stable/modules/preprocessing.html
6.3. Preprocessing data
The sklearn.preprocessing package provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream esti...
scikit-learn.org
데이터 스케일링 방법
- Scaler 선택 및 import
- Scaler 객체 생성
- train 데이터의 분포 저장 : scaler.fit(x_train)
- train 데이터 스케일링 : scaler.transform(x_train)
- test 데이터 스케일링 : scaler.transform(x_test)
원본 스케일로 다시 변경
scaler.inverse_transform(x_train_sc)
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris = pd.DataFrame(iris.data, columns=iris.feature_names)
iris['Class'] = load_iris().target
iris['Class'] = iris['Class'].map({0:'Setosa', 1:'Vergicolour', 2:'Virginica'})
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(iris.drop(columns = 'Class'), iris['Class'], test_size = 0.2, random_state=1004)
Min-max Scaler
정규화 방식으로 0~1 사이의 값으로 스케일링
이상치에 매우 민감하므로 이상치를 미리 정제한 후 수행
회귀에 유용
# 1. Scaler 선택 및 import
from sklearn.preprocessing import MinMaxScaler
# 2. Scaler 객체 생성
scaler = MinMaxScaler()
# 3. train 데이터의 분포 저장 : scaler.fit(x_train)
scaler.fit(x_train)
# 4. train 데이터 스케일링 : scaler.transform(x_train)
x_train_sc = scaler.transform(x_train)
# 5. test 데이터 스케일링 : scaler.transform(x_test)
x_test_sc = scaler.transform(x_test)
print("\t\t(min, max) (mean, std)")
print("Train_scaled\t(%.2f, %.2f) (%.2f, %.2f)"%(x_train_sc.min(), x_train_sc.max(), x_train_sc.mean(), x_train_sc.std()))
print("Test_scaled\t(%.2f, %.2f) (%.2f, %.2f)"%(x_test_sc.min(), x_test_sc.max(), x_test_sc.mean(), x_test_sc.std())) (min, max) (mean, std)
Train_scaled (0.00, 1.00) (0.44, 0.26)
Test_scaled (0.03, 0.97) (0.46, 0.27)
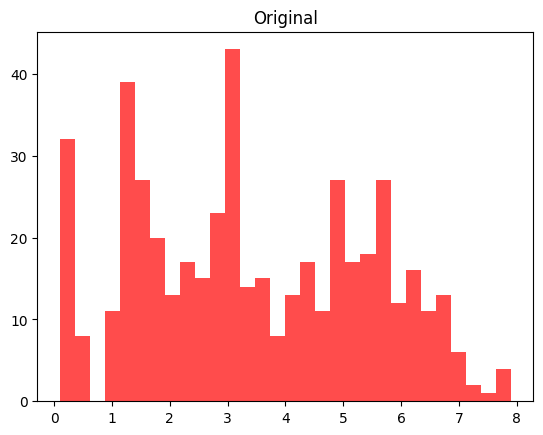 |
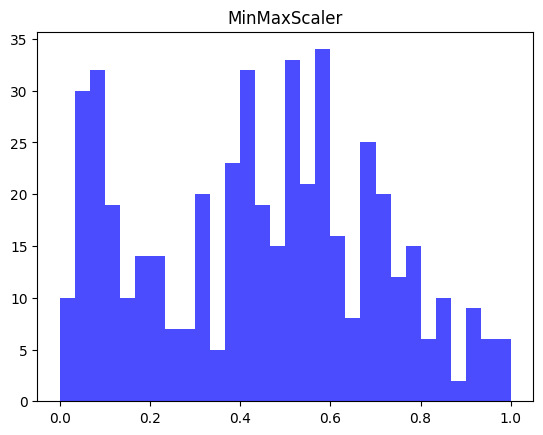 |
- 그 외 스케일링 방법
StandardScaler
표준화 방식
평균 0, 분산 1인 정규분포로 스케일링
이상치에 매우 민감하므로 이상치를 미리 정제한 후 수행
분류에 유용
MaxAbsScaler
정규화 방식
최대절대값과 0이 각각 1, 0이되도록 스케일링.
(모든 값 -1 ~ 1 사이로 표현 -> 데이터가 양수인 경우 MinMaxScaler와 동일)
이상치에 매우 민감하므로 이상치를 미리 정제한 후 수행
회귀에 유용
RobustScaler
중앙값과 사분위 값 활용하는 방식
중앙값을 0으로 설정하고, IQR을 사용해 이상치의 영향 최소화
quantile_range 파라미터를 조정해 더 넓거나 좁은 범위의 값을 이상치로 설정하여 정제할 수 있음.
(기본값 [0.25, 0.75])
'🥇 certification logbook' 카테고리의 다른 글
| 빅데이터분석기사 (빅분기) 실기 총 정리 / 시험 시작 전 확인 (0) | 2023.12.19 |
|---|---|
| [ADsP] 군집분석 (0) | 2023.06.18 |
| [python 통계분석] 교차분석(카이제곱 검정) (0) | 2023.06.18 |
| [python 통계분석] t-test 검정 (0) | 2023.06.18 |
| [python 데이터 핸들링] 판다스 연습 튜토리얼 - 07_Merge , Concat (0) | 2023.06.15 |
| [python 데이터 핸들링] 판다스 연습 튜토리얼 - 06_Pivot (0) | 2023.06.15 |
| [python 데이터 핸들링] 판다스 연습 튜토리얼 - 05_Time_Series (0) | 2023.06.13 |
| [python 데이터 핸들링] 판다스 연습 튜토리얼 - 04_Apply , Map (0) | 2023.06.13 |