[IBM course #4] Introduction to Neural Networks and PyTorch
Linear Regression Prediction
독립 변수 x, 종속 변수 y 사이의 관계를 선형 함수로 모델링.
모델: y = w*x + b (w: weight, b: bias)
예측값은 ŷ로 표기.
직접 텐서로 모델 정의
- requires_grad=True로 파라미터 정의
- forward() 함수에서 직접 선형 계산 수행
- 2행 1열 텐서 입력 → 각 행마다 선형 함수 적용하여 출력 텐서 생성 가능
w = torch.tensor(2.0, requires_grad = True)
b = torch.tensor(-1.0, requires_grad = True)
def forward(x):
yhat = w * x + b
return yhat
x = torch.tensor([[1.0]])
yhat = forward(x)
print("The prediction: ", yhat)
nn.Linear Class
- PyTorch 내장 클래스
- 자동으로 파라미터 생성 및 관리
import torch
import torch.nn as nn
model = nn.Linear(in_features=1, out_features=1) # 선형 레이어 객체 생성
x = torch.tensor([[1.0], [2.0]])
y = model(x) # 예측 수행
print("Output:\\n", y)
for param in linear.parameters(): # 파라미터 확인
print("Parameter:\\n", param)
print("State Dict:\\n", linear.state_dict()) # 파라미터 dict 확인
Custom Modules
class MyLinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1) # 입력 1, 출력 1
def forward(self, x):
return self.linear(x)
- nn.Module을 상속받아 사용자 정의 클래스 생성
- 내부에 nn.Linear 포함
- forward()에서 예측 정의
- 호출 시 forward 자동 실행됨
Linear Regression Training
dataset
(x, y) 쌍으로 구성된 N개의 샘플
예: 면적(x) → 가격(y), 금리(x) → 주가(y), 마력(x) → 연비(y)
noise assumption
실제 값은 이상적인 선형 관계 + 노이즈
노이즈는 가우시안 분포를 따름 → 대부분 0에 가까운 작은 값
Linear Regression
그래프상에서 직선을 데이터에 맞추는 작업
다양한 직선 중 가장 잘 맞는 하나를 찾음
Loss Function
평균 제곱 오차 (MSE)가 사용됨
파라미터(w, b)에 대한 함수
MSE 값이 최소가 되는 파라미터 조합이 가장 좋은 직선
Loss Function
Loss?
모델 예측값과 실제 값의 차이를 제곱 → 손실
손실이 작을수록 모델이 잘 예측하고 있다는 뜻
Parameter와 Loss Function
모델의 예측값은 파라미터에 따라 달라짐
손실 함수는 “파라미터(slope) → 손실값”의 함수로 생각 가능
모델 학습은 곧 손실(loss) 을 줄이기 위한 파라미터 최적화 과정이라고 할 수 있으며,
이 때 핵심 도구가 바로 기울기(도함수)임.
Parameter 최적화 → 기울기를 이용해 손실을 최소화 하는 과정
즉, 손실 함수의 기울기(미분) = 파라미터 조정 방향
함수의 최솟값은 도함수가 0이 되는 지점에 존재
파라미터가 1~2개 정도라면 직접 수식 풀기 가능하겠지만,
하지만 딥러닝 모델은 수백만 개의 파라미터 → 해석적으로 미분 = 불가능
따라서 수치적 방법을 사용함.
Gradient Descent
함수의 최소값을 찾기 위한 수치적 방법
복잡한 모델의 경우 해석적으로 최소값을 구하기 어렵기 때문에, 기울기(도함수)를 이용해 반복적으로 파라미터를 조정하게 됨.
파라미터 업데이트 방식
parameter -= η * derivative
기울기 > 0 → 손실 증가 방향이므로 파라미터를 감소시켜야 함
기울기 < 0 → 파라미터를 증가시켜야 함
이 과정을 반복(iterative)하여 점차 최소값으로 수렴
학습률(η, learning rate)
η는 한 번에 이동하는 거리(점프 크기)를 결정
학습률 설정 문제
- 너무 크면 최소값을 지나쳐버림
- 너무 작으면 수렴이 매우 느림
종료 조건
- 고정된 반복 횟수 (ex: 3번 반복) → epoch 설정
- 손실이 더 이상 줄지 않거나 오히려 증가할 때 → Early Stopping
Cost
Loss는 하나의 샘플에 대한 오차를 측정하지만, 실제 학습에서는 여러 샘플(데이터 전체)에 대한 손실을 고려해야 함. → 전체 손실의 합계 또는 평균을 비용(cost)이라 부름
PyTorch에서는 보통 Loss Function ≒ Cost Function
수식적 이해
Cost = f(w, b)
비용 함수는 기울기(w)와 편향(b)의 함수
w는 x-y의 관계 제어, b는 수평 이동 제어 역할
기울기에 대한 도함수
경사하강법을 수행하기 위해 비용 함수의 도함수를 사용
- 모든 기울기 값이 음수 → 파라미터에 큰 양의 값이 더해짐 → 큰 폭의 이동
- 반대로 기울기 값이 모두 양수 → 큰 음의 값이 더해짐 → 파라미터 값 크게 감소
상쇄되는 경우
데이터 포인트가 선의 양쪽에 하나씩 위치하면,
도함수 값이 서로 상쇄 → 기울기 ≈ 0 → 업데이트 거의 없음
배치(Batch)의 개념
모든 샘플을 한 번에 사용하는 경우 Batch Gradient Descent
일부 묶음을 하나의 배치로 사용하는 경우 Mini-Batch Gradient Descent
한 번에 하나의 샘플만 사용하여 업데이트하는 경우 Stochastic Gradient Descent
Linear Regression PyToch
1. 파라미터 및 데이터 준비
w 텐서를 만들고 requires_grad=True 설정
X값에 따라 y = -3x 직선을 생성하고 노이즈 추가
import torch
# 학습 파라미터
w = torch.tensor(-10.0, requires_grad = True)
# 데이터 생성
x = torch.arange(-3, 3, 0.1).view(-1, 1)
f = -3 * X
Y = f + 0.1 * torch.randn(x.size()) # -3x + 노이즈
2. forward 함수 정의
ŷ = w * x
def forward(x):
return w * x
3. 손실 함수 정의
평균 제곱 오차(MSE) 사용
def loss_fn(y_hat, y):
return torch.mean((y_hat - y) ** 2)
4. 학습 설정
학습률: 0.1
에폭: 4번
lr = 0.1
for epoch in range(4):
y_hat = forward(x)
loss = loss_fn(y_hat, y)
loss.backward() # 기울기 계산
w.data -= lr * w.grad.data # 파라미터 업데이트
w.grad.data.zero_() # 다음 반복을 위한 그래디언트 초기화
반복의 효과
초기에는 기울기(도함수) 가 크므로 파라미터가 크게 업데이트됨
반복할수록 기울기가 작아지고 → 업데이트 폭도 줄어듬
결과적으로 점진적으로 수렴
손실 변화 추적
losses = []
for epoch in range(15):
...
losses.append(loss.item())
각 반복마다 손실값 .item()으로 수집
matplotlib으로 손실 추이 시각화 가능
PyTorch Linear Regression Training Slope and Bias
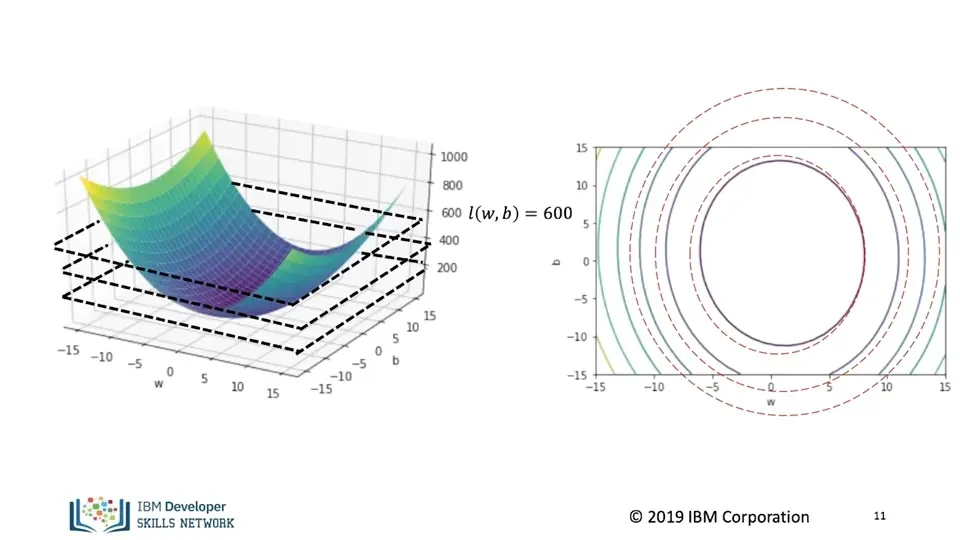
비용 곡면 (Cost Surface)
비용 함수는 Cost(w, b) 형태의 2변수 함수 → 3D 곡면
수직축: 비용값, 수평축: w, b
Contour Plot
같은 비용 값을 가지는 파라미터 조합을 선으로 연결
→ 마치 지도상의 등고선과 유사
경사하강법 구현
1. 모델정의
forward(x) = w * x + b
w, b, x, y 모두 텐서로 초기화
def forward(x):
return w * x + b
# 파라미터 초기화
w = torch.tensor(-15.0, requires_grad = True)
b = torch.tensor(-10.0, requires_grad = True)
x = torch.arange(-3, 3, 0.1).view(-1, 1)
f = 1 * X - 1
y = f + 0.1 * torch.randn(x.size())
2. 비용 함수 정의 (MSE)
def loss_fn(y_hat, y):
return torch.mean((y_hat - y) ** 2)
3. 수행
loss.backward() 호출 후 w, b 업데이트
각 반복(epoch)마다 w, b가 최소값으로 수렴
lr = 0.1
for epoch in range(15):
y_hat = forward(x)
loss = loss_fn(y_hat, y)
loss.backward()
w.data -= lr * w.grad.data
b.data -= lr * b.grad.data
w.grad.data.zero_()
b.grad.data.zero_()
수학적 개념 정리
다변수 함수의 도함수 = 편도함수 (Partial Derivative)
모든 편도함수를 모은 벡터 = 그래디언트 (Gradient)
→ 비용 함수의 가장 빠른 감소 방향을 알려줌
'🥇 certification logbook' 카테고리의 다른 글
| [Coursera/IBM course #6] Capstone Project 메모 (3) | 2025.07.20 |
|---|---|
| [Coursera/IBM course #5] Convolution 연산 기본 개념 (4) | 2025.07.19 |
| [Coursera/IBM course #5] 신경망 (Neural Net) (1) | 2025.07.16 |
| [Coursera/IBM course #5] Softmax (0) | 2025.07.13 |
| [Coursera/IBM course #4] Dataset (0) | 2025.06.07 |
| [Coursera/IBM course #4] Tensors (2) | 2025.06.07 |
| [Coursera/IBM course #3] 강화학습(Reinforcement Learning) (2) | 2025.06.04 |
| [Coursera/IBM course #3] Advanced Keras Techniques (2) | 2025.06.01 |